
Real-Time Data Streaming & Analytics Pipeline with Kafka & Flink


Objective
Why do this? To get a better understanding of powerful technologies in the industry: Apache Flink, Kafka, Elasticsearch, and Docker in the world of Data Engineering for real time streaming data processing & analytics
The best way to learn these technologies is to get your hands ‘dirty’ and code. I had to set everything up from scratch, right down from installing Docker, Flink, Maven & setting up the environment. It was a great experience setting this up. Of course, thanks to the ton of resources available online these days.
Background
Streaming real-time data directly into Kafka along with Apache Flink that will listen to the event streams that will come from Kafka. Once the data is received, Flink will stream data into Postgres along with a bit of transformation.
Flink will also stream the data to elastic search along with real-time visualization on elasticsearch with Kibana. I then create a dashboard in Kibana where real-time data streams are visualized.
Tools used : Docker, Kafka(Confluent), Maven, Apache Flink, Postgres, Elasticsearch, Kibana.
IDE: Visual Studio Code & IntelliJ Idea
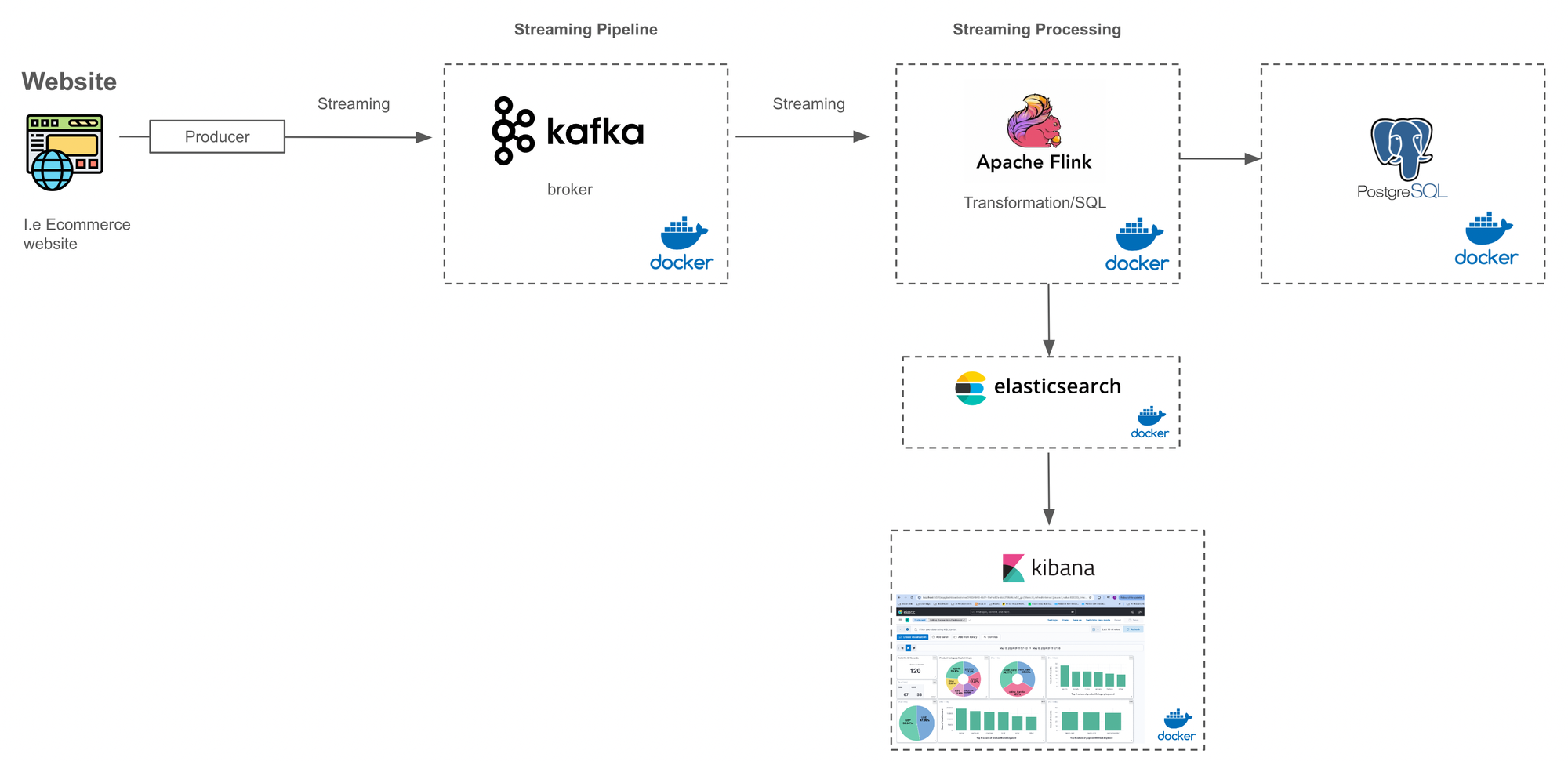
Components of the Data Pipeline
- Kafka: Kafka acts as the central data streaming platform where real-time data is ingested. It serves as a distributed messaging system that allows you to publish and subscribe to streams of records.
- Apache Flink: Flink is a stream processing framework that processes and analyzes real-time data streams. It integrates seamlessly with Kafka to consume event streams, perform transformations, and then stream the processed data to multiple destinations.
- PostgreSQL: PostgreSQL is used as the destination database where the processed data from Flink is stored. Flink performs transformations on the incoming data streams before persisting them into PostgreSQL.
- Elasticsearch: Elasticsearch is a distributed search and analytics engine that is well-suited for storing and querying large volumes of real-time data. Flink streams data directly into Elasticsearch, enabling you to perform real-time analytics and visualization.
- Kibana: Kibana is a data visualization and exploration tool that works in conjunction with Elasticsearch. It allows you to create interactive dashboards and visualizations to monitor and analyze the data stored in Elasticsearch.
Flow of Data in the Pipeline
- Data Ingestion: Real-time data is streamed directly into Kafka from various sources. This could include data from sensors, applications, or any other streaming data source.
- Processing with Flink: Flink consumes the data streams from Kafka, applies transformations or business logic as needed, and then streams the processed data to multiple destinations simultaneously.
- Data Storage in PostgreSQL: Flink streams the transformed data into PostgreSQL, where it is persisted for further analysis or reporting. This data may be structured in a relational format suitable for querying.
- Data Indexing in Elasticsearch: Simultaneously, Flink streams the processed data into Elasticsearch, where it is indexed and made available for real-time search and analytics.
- Visualization with Kibana: Kibana connects to Elasticsearch to visualize the real-time data streams through interactive dashboards and visualizations. Users can monitor key metrics, trends, and anomalies in the data in real-time.
Advantages and Considerations
- Real-Time Insights: By leveraging Kafka, Flink, Elasticsearch, and Kibana, you can gain real-time insights into your streaming data, enabling you to make timely decisions and respond to events as they occur.
- Scalability: The distributed nature of Kafka, Flink, and Elasticsearch allows the pipeline to scale horizontally to handle large volumes of data and increasing processing demands.
Setting up the Environment
Setting up with Docker Environment
We start by creating the docker-compose.yml - in this we will have the different services that we will be working with.
Container Name: zookeeper (Zookeeper Confluent Zookeeper, confluentinc/cp-zookeeper:7.4.0
Container Name: broker (CP Kafka 7.4.0,confluentinc/cp-kafka:7.4.0)
Container Name: postgres (Postgres Database)
Container Name: es-container (Elasticsearch 8.11.1)
Container Name: kb-container (Kibana 8.11.1)
Start the Docker Environment
docker compose up -d
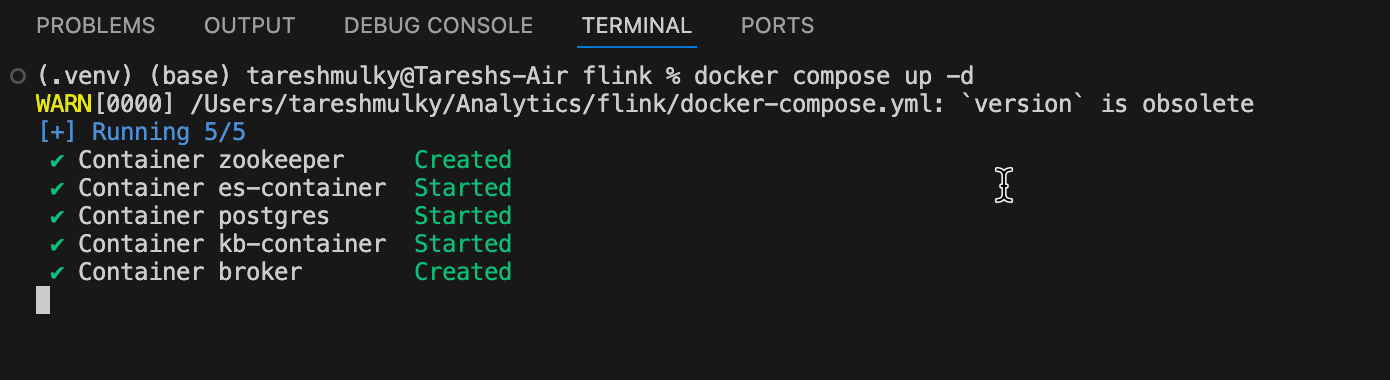
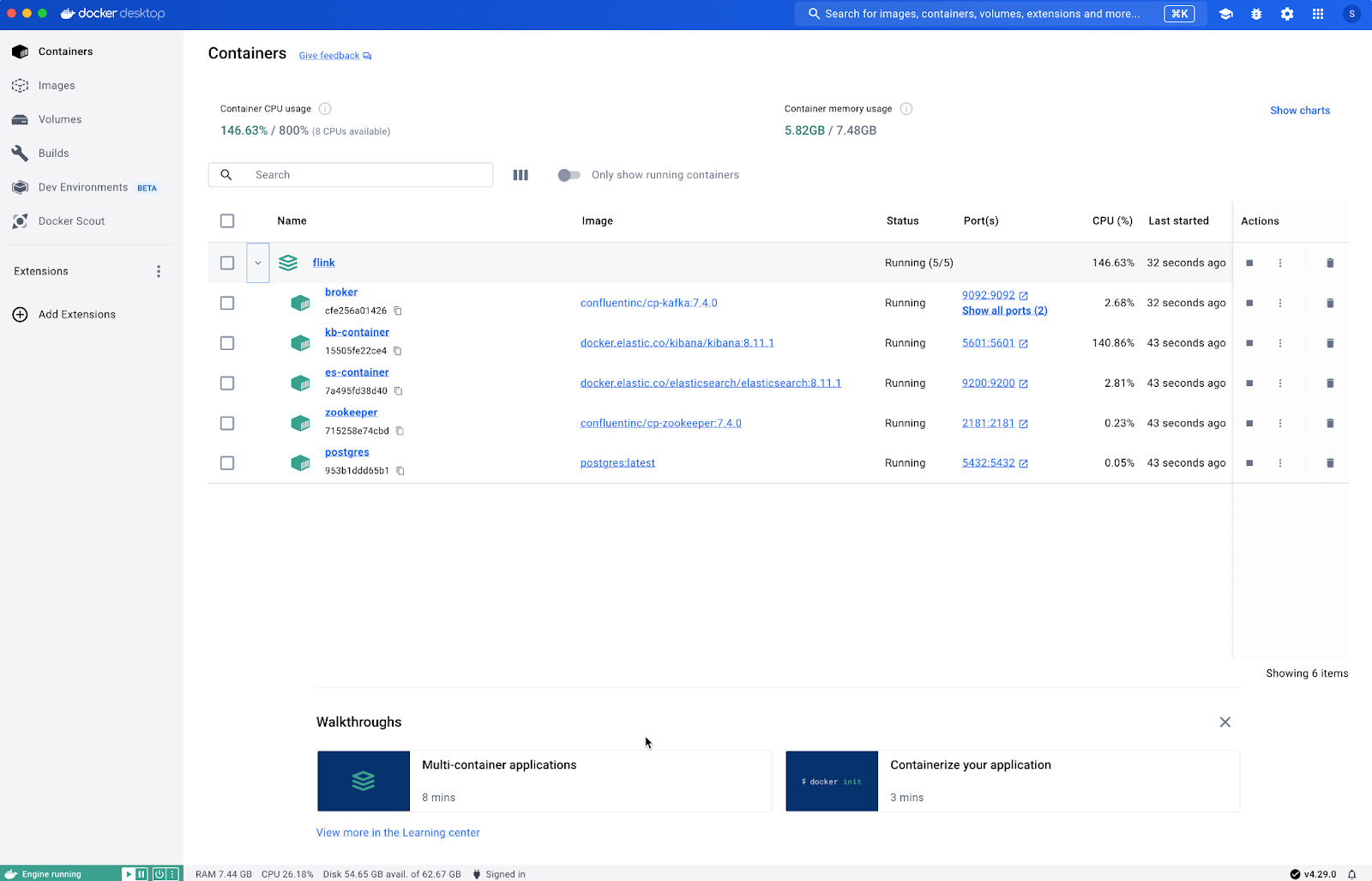
Push Data into Kafka Queue
We want to push data into the Kafka Queue in a specific format.
Faker is a Python library used for generating fake data. Great for testing scenarios where realistic but not sensitive data is needed. Faker allows developers to create randomized data such as names, addresses, emails, and much more, which can be useful for populating databases, creating test environments, or generating sample data for demonstrations.
The confluent_kafka library is a popular Python library for interacting with Apache Kafka, a distributed streaming platform. It provides support for both consuming messages from Kafka topics and producing messages to Kafka topics. In Apache Kafka, serialization is the process of converting data from its internal representation into a format that can be sent over the network or stored in Kafka topics. Common serialization formats include JSON, Avro, Protocol Buffers, and others.
Producer will be the SerializingProducer() from Confluent Kafka. The data will be in JSON format.
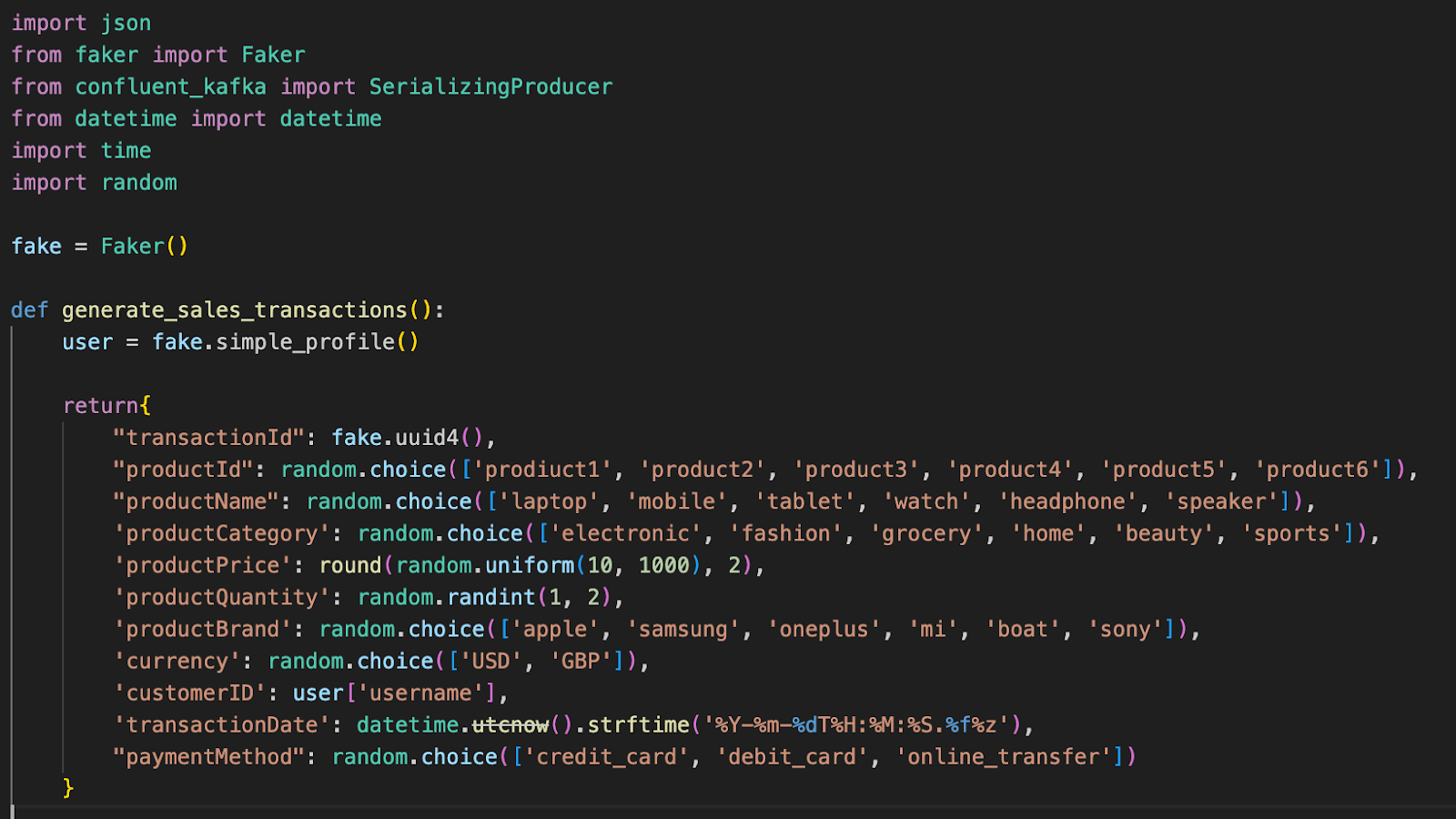
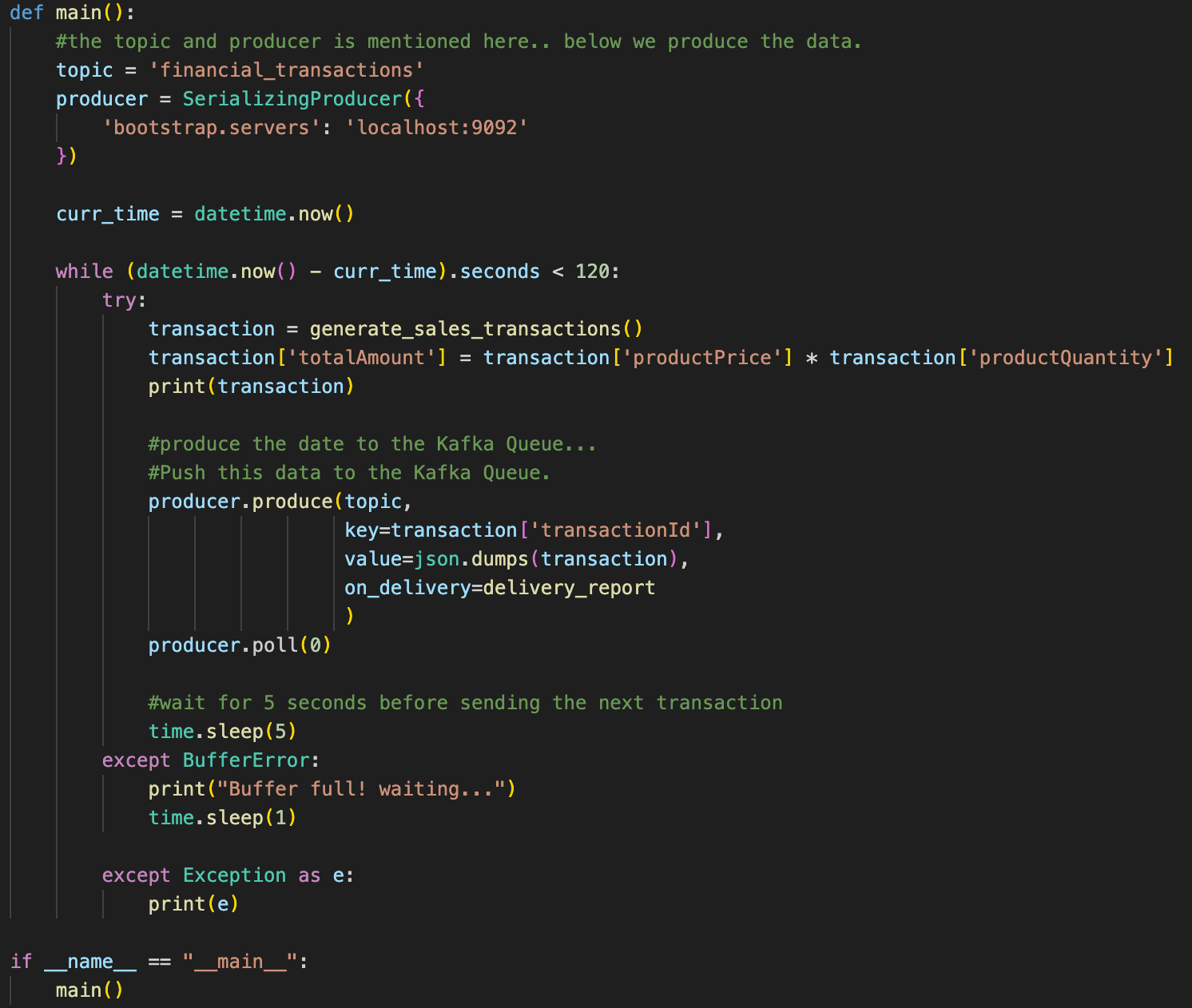
Kafka producer using a SerializingProducer class.
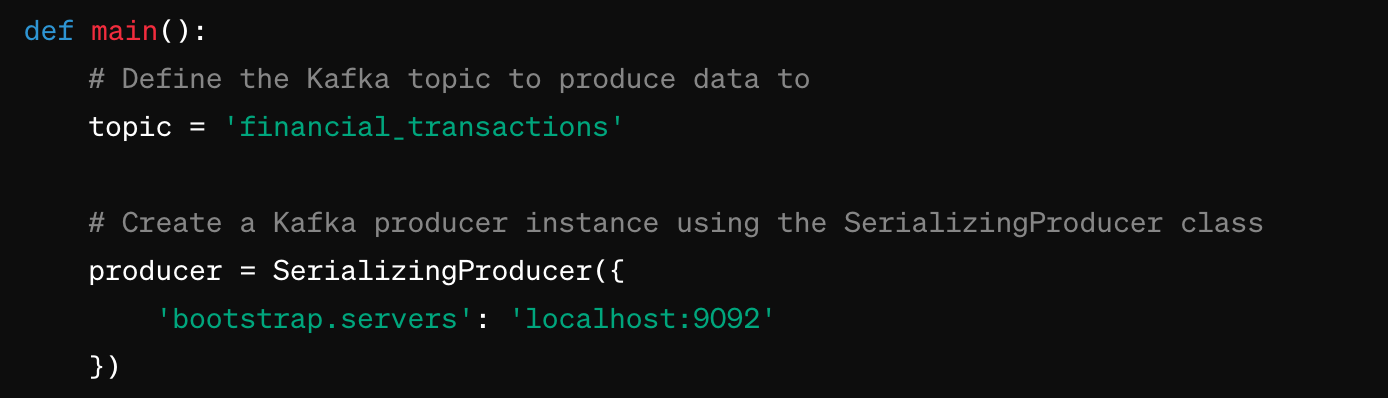
Within the def main() function:
- The Kafka topic 'financial_transactions' is specified. This is the destination topic where the produced data will be sent.
- A Kafka producer is created using the SerializingProducer class. It's initialized with the bootstrap servers configuration pointing to localhost:9092. The bootstrap servers are the initial brokers that the producer will use to establish connections to the Kafka cluster.

This code above efficiently produces a message to the Kafka topic financial_transactions with the specified key and value. It also ensures that the message is immediately sent to the broker without waiting.
Here is what’s happening:
producer.produce(): This method is used to produce a message to the specified Kafka topic (financial_transactions in this case). It takes several arguments:
- topic: The Kafka topic to which the message will be produced (‘financial_transactions’).
- key: (Optional) The key associated with the message. It's often used for partitioning messages in Kafka.
- value: The value of the message.
- on_delivery: (Optional) A callback function that will be invoked when the message delivery status is acknowledged by the broker. This allows you to handle delivery status asynchronously.
Run the Producer
python main.py

Kafka Consumer
(.venv) (base) tareshmulky@Tareshs-Air flink % docker exec -it broker /bin/bash
Run the following script
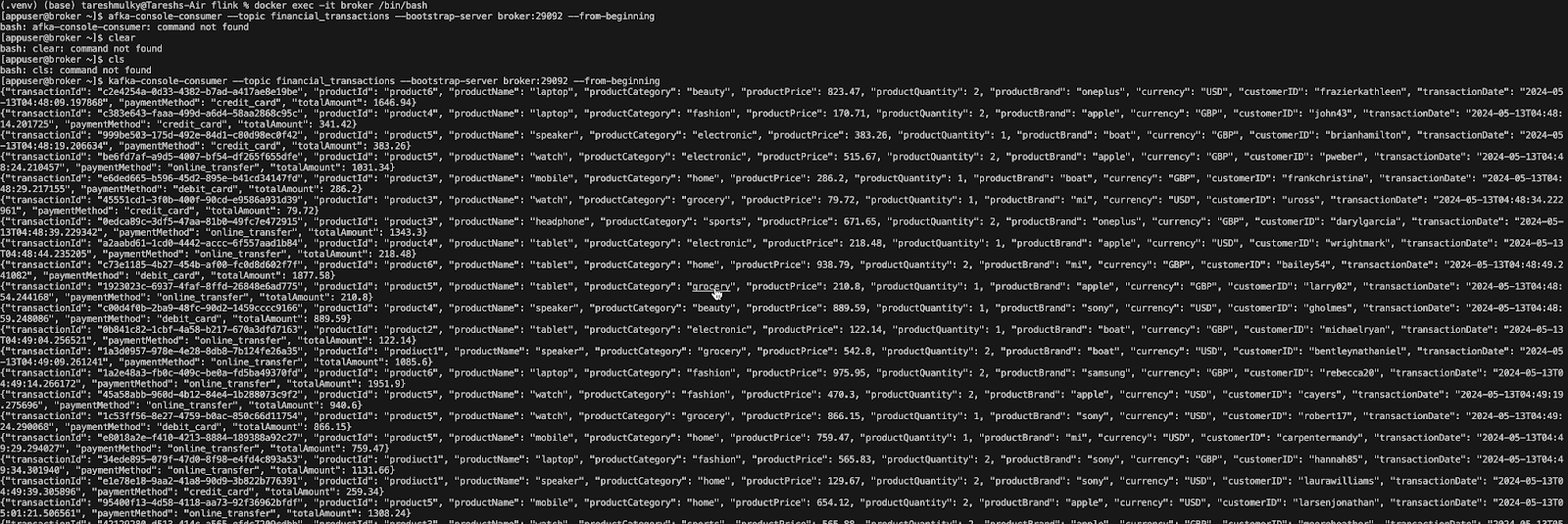
[appuser@broker ~]$ kafka-console-consumer --topic financial_transactions --bootstrap-server broker:29092 --from-beginning
The command kafka-console-consumer is used to consume messages from a Kafka topic directly from the command line. The Kafka console consumer will start consuming messages from the "financial_transactions" topic and print them to the console in real-time.

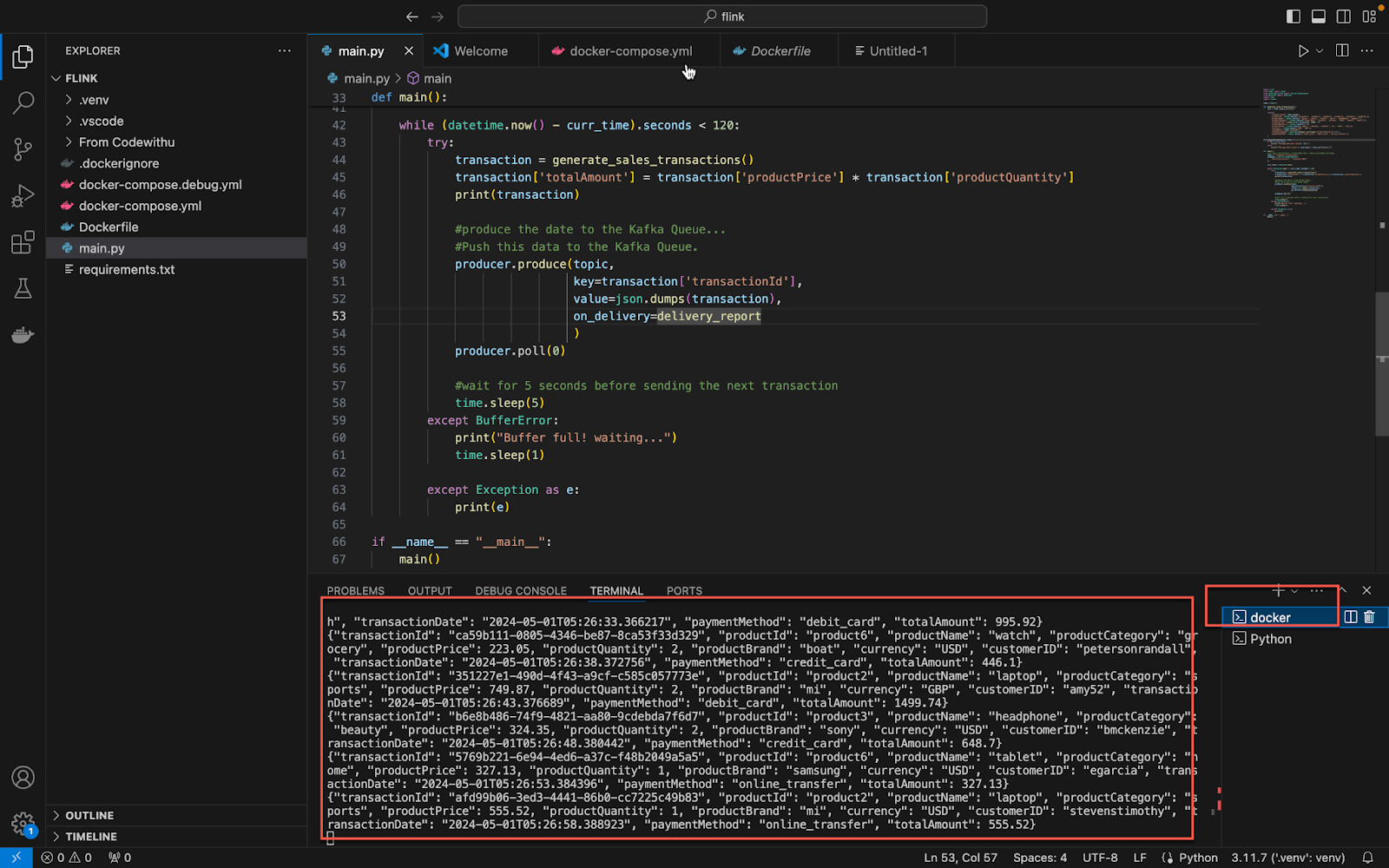
You should be able to see the topics in Docker as well.
To check if the topics are in. Run the following command. It will list the topics
kafka-topics --list --bootstrap-server broker:29092
Run the following command to view the results of the topic, from the beginning.
kafka-console-consumer --topic financial_transactions --bootstrap-server broker:29092 --from-beginning
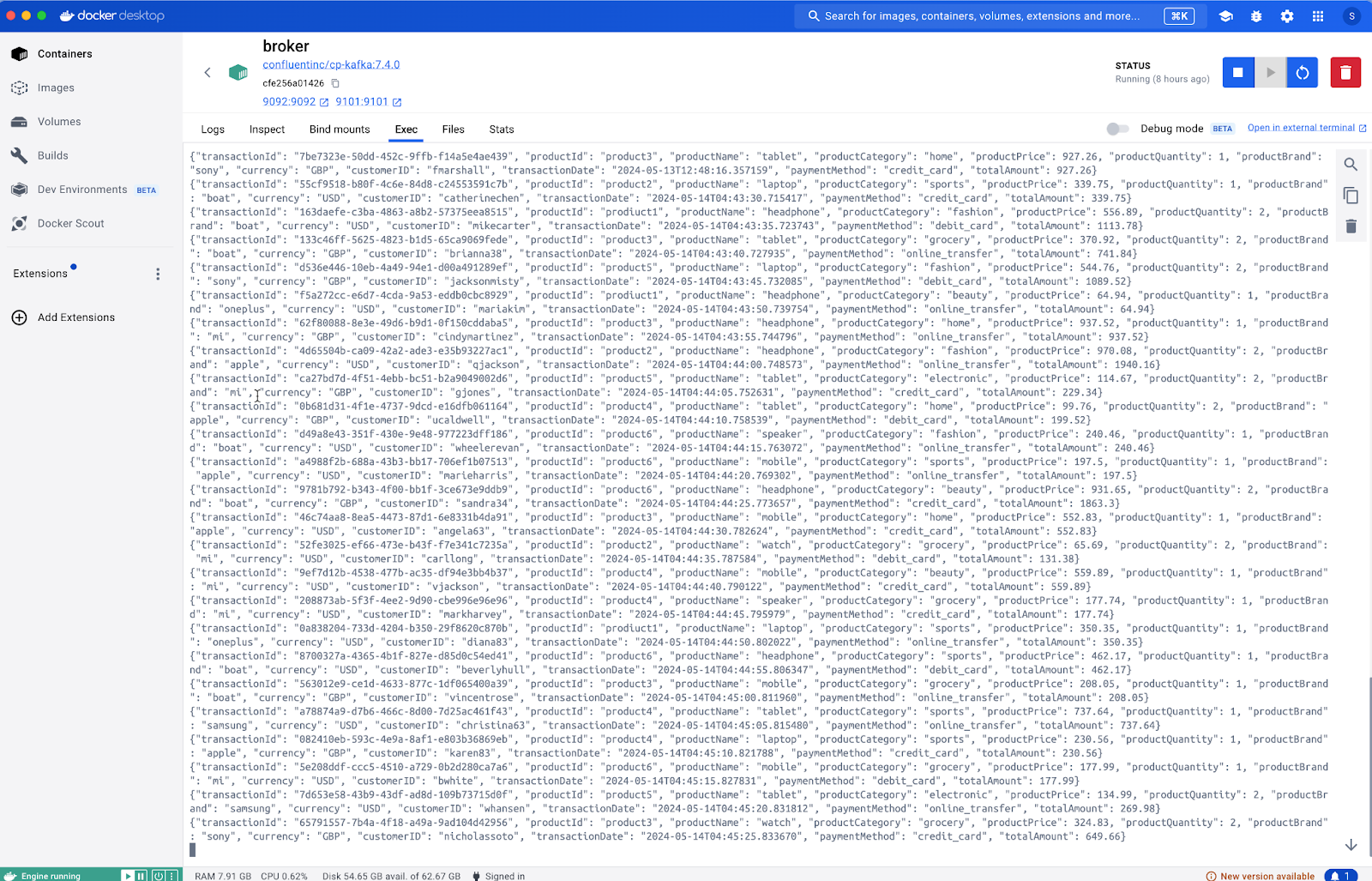
Up to this point, we have created the structure and the producer is streaming the content.
Apache Flink
Stream Processing
We will leverage the Maven Central Catalog hence we need to add dependencies in the Pom.xml file.
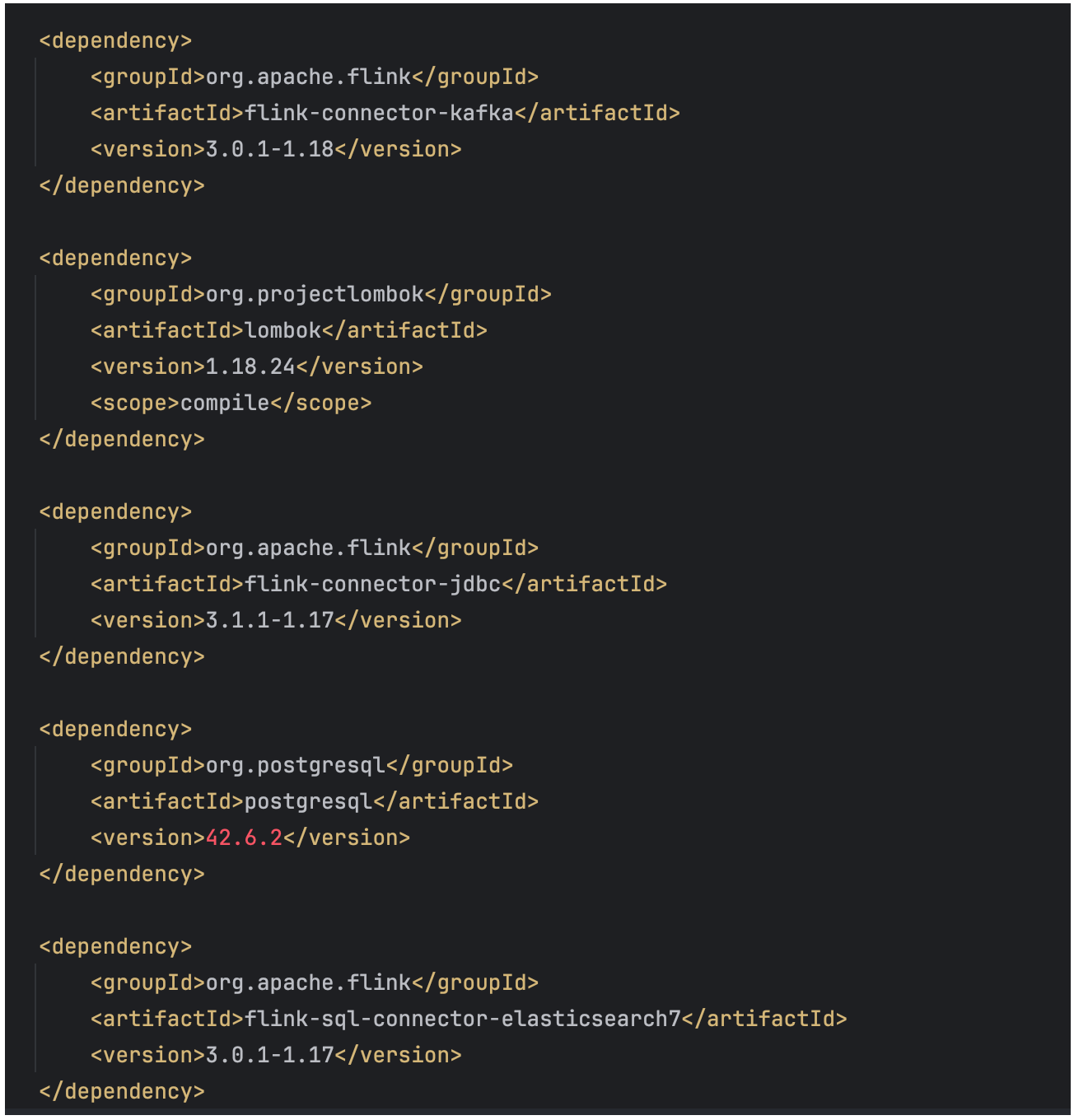
As we are working with event streams that are coming in from Kafka. We will use the StreamExecutionEnvironment to get the event streams coming in from Kafka. We need to deseriale the data from Kafka into a particular DTO (Data Transfer Object).
The reason being is that the raw data from Kafka is typically in binary format, as Kafka stores and transmits messages in binary form for efficiency and flexibility. However, Kafka itself is agnostic to the format of the data it stores and transports. It treats messages as byte arrays, allowing you to use any serialization format that suits your requirements.
Deserializing data from Kafka
Deserializing data from Kafka into a particular DTO (Data Transfer Object) means converting the raw binary or string data received from Kafka topics into instances of a specific Java class that represents the structure of the data.
Here's what this process typically involves:
- Defining the DTO: First, we define a Java class that represents the structure of the data you expect to receive from Kafka. This class is often referred to as a DTO. It typically consists of fields that correspond to the attributes of the data, along with getter and setter methods for accessing and modifying these attributes.
- Deserialization Logic: Next, we write deserialization logic to map the raw data received from Kafka into instances of the DTO class. The deserialization logic depends on the format of the data (e.g., JSON, Avro, XML) and the deserialization library or framework you're using (e.g., Jackson, Gson, Apache Avro). This logic typically involves parsing the raw data and populating the fields of the DTO object accordingly.
- Mapping to DTO: As messages are consumed from Kafka, the deserialization logic is applied to each message to convert it into an instance of the DTO class. Once deserialized, you can work with the data in its structured form, accessing individual attributes through the DTO object's getter methods.
In the context of Apache Flink, when you specify a deserialization schema for a Kafka consumer, you're essentially defining how Kafka messages should be deserialized into instances of a specific DTO class. This allows you to work with the data in a structured and meaningful way within your Flink streaming application.
Why do we deserialize data from Kafka?
Deserializing data from Kafka into a particular DTO (Data Transfer Object) serves several important purposes in software development:
- Data Structure Representation: Deserializing data into a DTO allows you to represent the structure of the data in a clear and meaningful way. By defining a Java class that mirrors the structure of the data, you can encapsulate the attributes and relationships of the data within the DTO, making it easier to understand and work with.
- Serialization and Deserialization: DTOs are often used in conjunction with serialization and deserialization frameworks to convert data between different representations (e.g., binary, JSON, XML). Deserializing data from Kafka into a DTO allows you to convert the raw data received from Kafka into a structured format that can be easily manipulated and processed by the application.
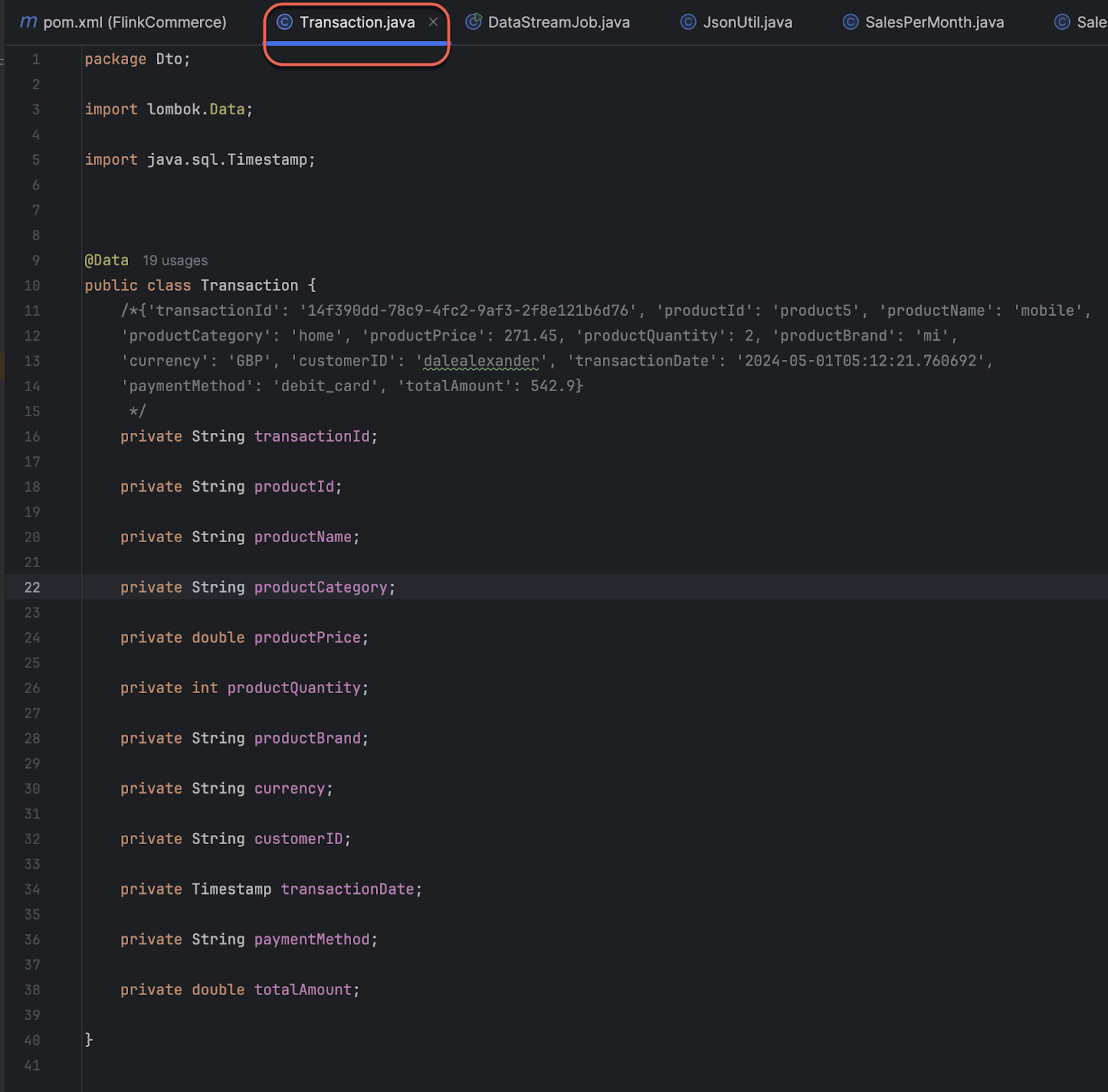
In the screen shot above, we deserialize the data into Transactions.
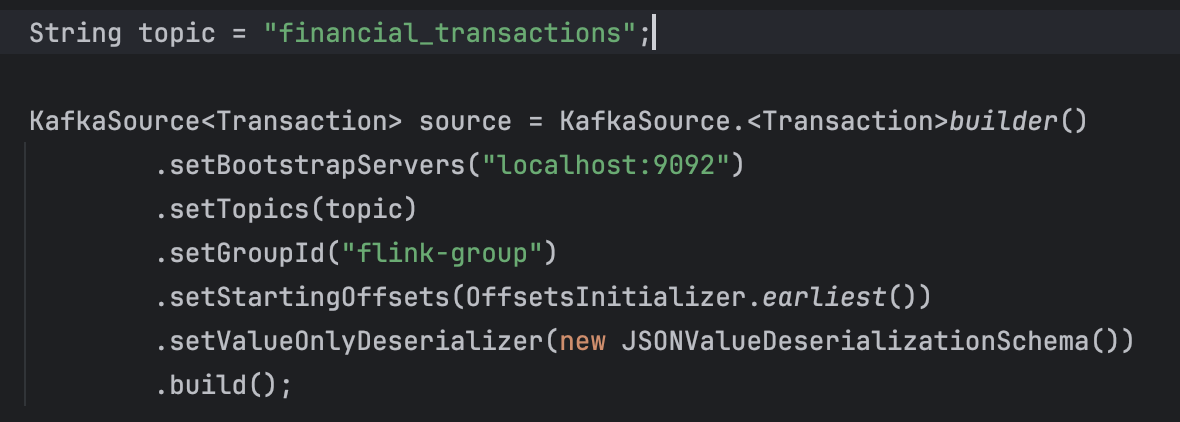
SetValueOnlyDeserializer - is going to deserialize the data that is coming from Kafka into the model. It is important to have a deserializer as once data comes from Kafka, it needs to be deserialized. Hence we need to create the JSONValueDeserializationSchema()
The code above is using the Flink Kafka connector to set up a Kafka source for consuming data streams from Kafka topics in a Flink streaming application. Overall, this code sets up a Kafka source in Flink for consuming data streams from Kafka topics, specifying the Kafka configuration, deserialization schema, consumer group ID, and starting offsets. It allows Flink to ingest Kafka messages and process them as instances of the Transaction class within a Flink streaming application.
- setBootstrapServers("localhost:9092"): Sets the list of Kafka bootstrap servers to connect to. In this case, it's set to "localhost:9092".
- setTopics(topic): Specifies the Kafka topics from which the Flink Kafka source will consume data. The topic variable likely contains the name of the topic or a list of topics.
- setGroupId("flink-group"): Sets the Kafka consumer group ID. Consumer group ID is used to uniquely identify consumers within the same consumer group. This ensures that each message in the topic is consumed by only one consumer within the group.
- setStartingOffsets(OffsetsInitializer.earliest()): Specifies the starting offsets from which the Flink Kafka source will begin consuming messages. OffsetsInitializer.earliest() sets the starting offsets to the earliest available offset in the Kafka topic, meaning it starts consuming messages from the beginning of the topic.
- setValueOnlyDeserializer(new JSONValueDeserializationSchema()): Specifies the deserialization schema to use for deserializing Kafka message values into instances of the Transaction class. JSONValueDeserializationSchema is a custom deserialization schema that deserializes JSON-formatted messages into instances of the Transaction class.
- build(): Builds and returns the Kafka source configured with the specified properties and settings. The KafkaSource<Transaction> type indicates that the source will emit instances of the Transaction class.
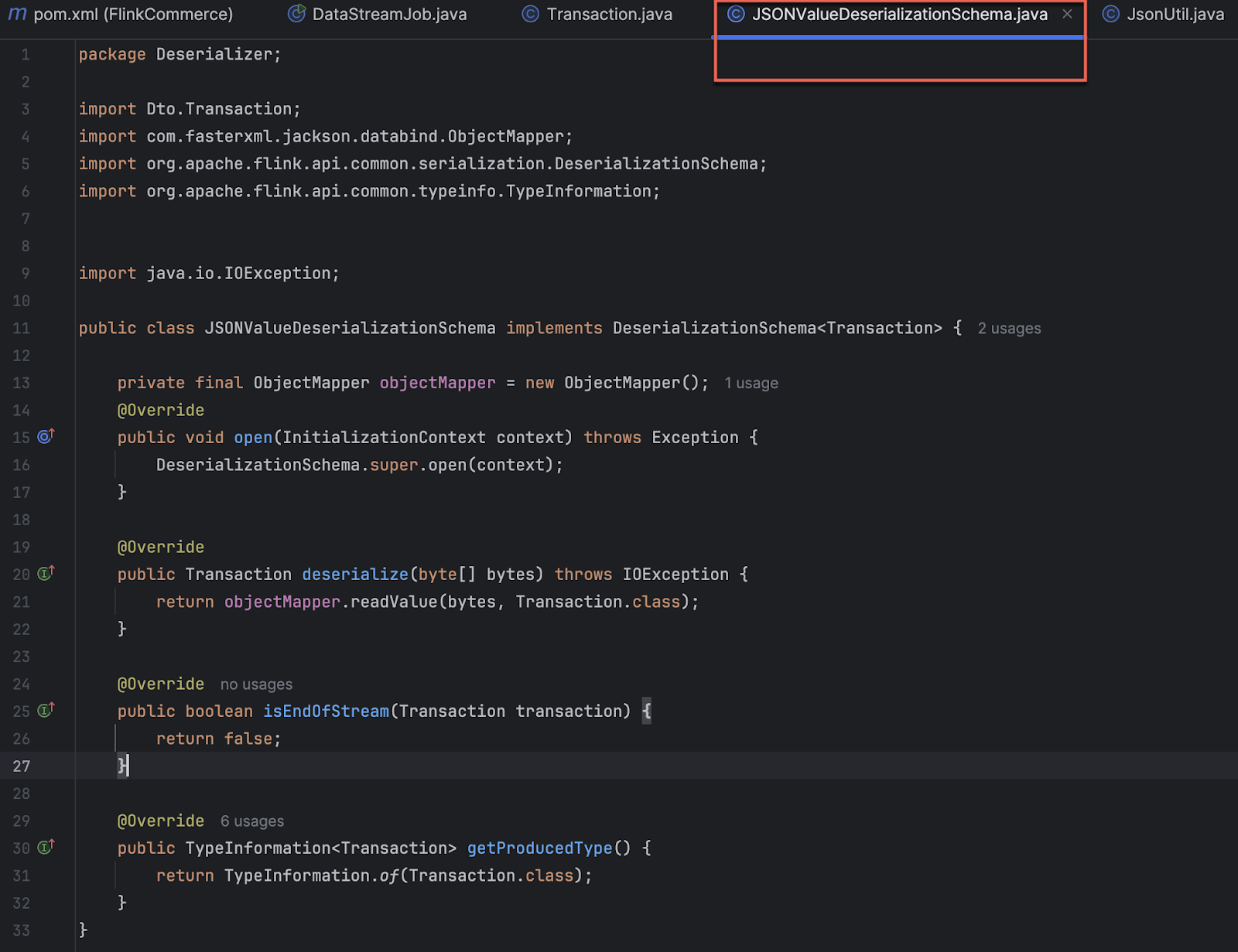
The above code, JSONValueDeserializationSchema.java - to implement a custom deserialization schema in Apache Flink for deserializing Kafka messages into instances of the Transaction class.
- import Dto.Transaction;: Imports the Transaction class from the Dto package. This is the class representing the structure of the data being deserialized.
- import com.fasterxml.jackson.databind.ObjectMapper;: Imports the ObjectMapper class from the Jackson library for JSON serialization and deserialization.
- import org.apache.flink.api.common.serialization.DeserializationSchema;: Imports the DeserializationSchema interface from Apache Flink, which is used for deserializing data in Flink applications.
- import org.apache.flink.api.common.typeinfo.TypeInformation;: Imports the TypeInformation class from Apache Flink, which represents the type information of data produced or consumed by Flink operators.

import com.fasterxml.jackson.databind.ObjectMapper;is used to import the ObjectMapper class from the Jackson library. Jackson is a popular JSON (JavaScript Object Notation) processing library for Java that provides functionalities for parsing JSON data into Java objects (deserialization) and serializing Java objects into JSON data (serialization).
The ObjectMapper class is a central class in Jackson that provides methods for reading and writing JSON data. Using the ObjectMapper class, you can easily serialize Java objects to JSON strings and deserialize JSON strings back into Java objects, making it a powerful tool for working with JSON data in Java applications.
- ObjectMapper: This is the main class in Jackson used for reading and writing JSON. It provides methods for converting JSON data to Java objects and vice versa, handling JSON serialization and deserialization, and configuring various serialization and deserialization settings.
We implement the DeserializationSchema, the object of transaction is passed in there DeserializationSchema<Transaction>
DataStreamJob.java
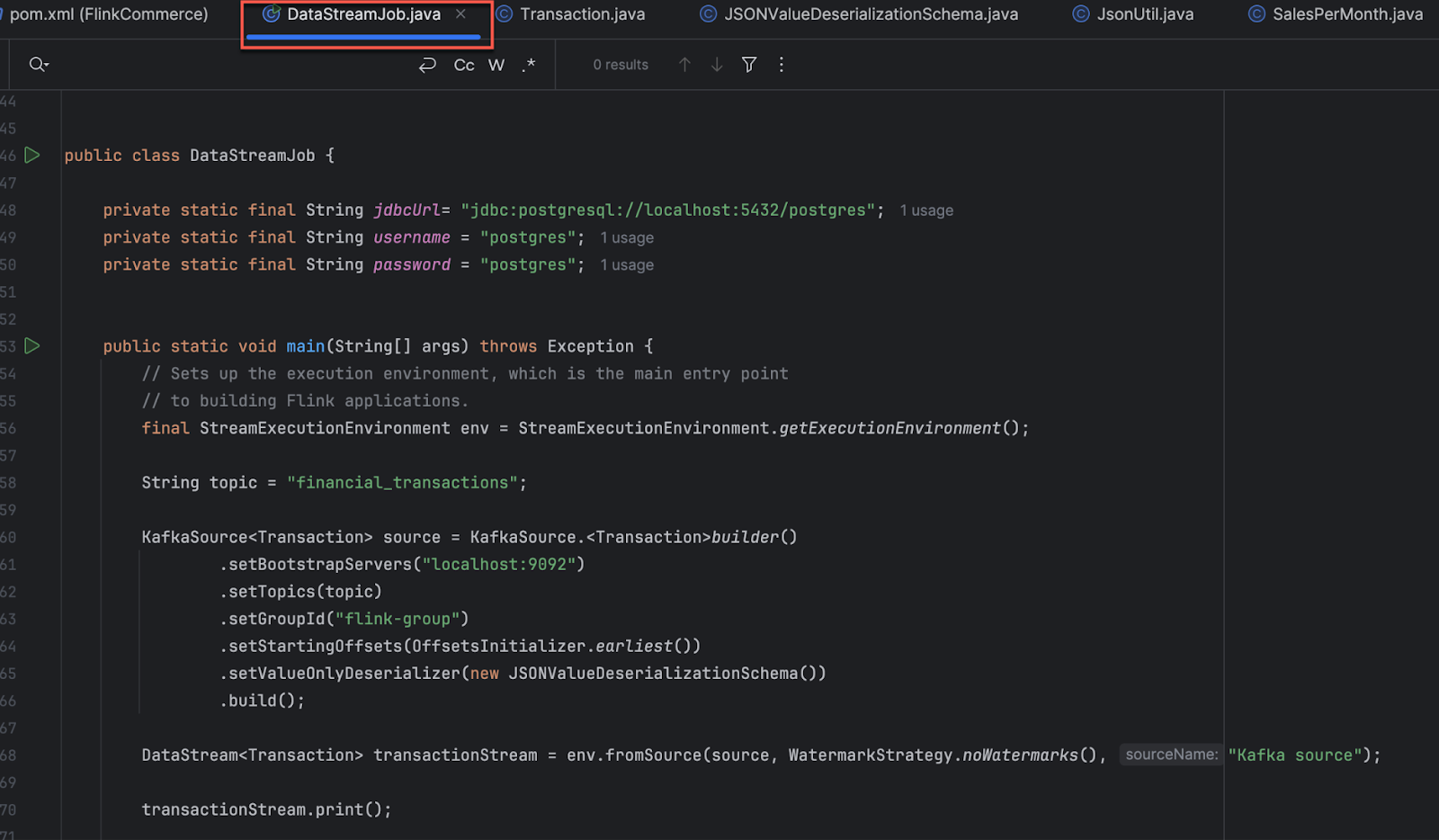

The code final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); initialises the Flink execution environment for a streaming application.
- StreamExecutionEnvironment: This class is the main entry point for creating Flink streaming applications. It provides methods for configuring the execution environment, defining sources and sinks, and specifying transformations on data streams.
- getExecutionEnvironment(): This static method is used to obtain an instance of StreamExecutionEnvironment. It returns the execution environment for running Flink streaming jobs.
- final: This keyword declares that the variable env is a final variable, meaning its value cannot be reassigned after initialization. In this case, env holds a reference to the execution environment, and making it final ensures that it cannot be accidentally changed later in the code.
KafkaSource<Transaction> source : Deserialize the incoming data from Kafka as mentioned above.

The code is creating a DataStream of Transaction objects in Apache Flink using a Kafka source with a custom deserialisation schema.
- env: This is an instance of StreamExecutionEnvironment, which represents the execution environment for the Flink job.
- fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka source"): This method is used to create a DataStream from a custom source. In this case, the source variable represents the Kafka source configured to consume data streams from Kafka topics.
- WatermarkStrategy.noWatermarks(): This specifies that no watermarks are being used for event time processing. Watermarks are used to track progress in event time processing and handle out-of-order events.
- "Kafka source": This is a string identifier for the source, which can be used for debugging and monitoring purposes.
- DataStream<Transaction>: This is the type of the resulting DataStream, which represents a stream of Transaction objects.
DataStream: This is a class provided by Apache Flink for representing a stream of elements in a Flink streaming application. A DataStream represents a potentially infinite sequence of data elements that are processed continuously over time. Using the DataStream class, you can perform various operations and transformations on streaming data, such as filtering, mapping, aggregating, and joining, to implement complex streaming data processing pipelines. DataStream is a fundamental class in Apache Flink for working with streaming data and building real-time data processing applications.
To test the code. You would need to compile & create the package and then execute the jar file.
To test the code, you would need to compile and run the script.
mvn clean
mvn compile
mvn package
Once you run the mvn package script - the Jar file will be created in the Target folder.
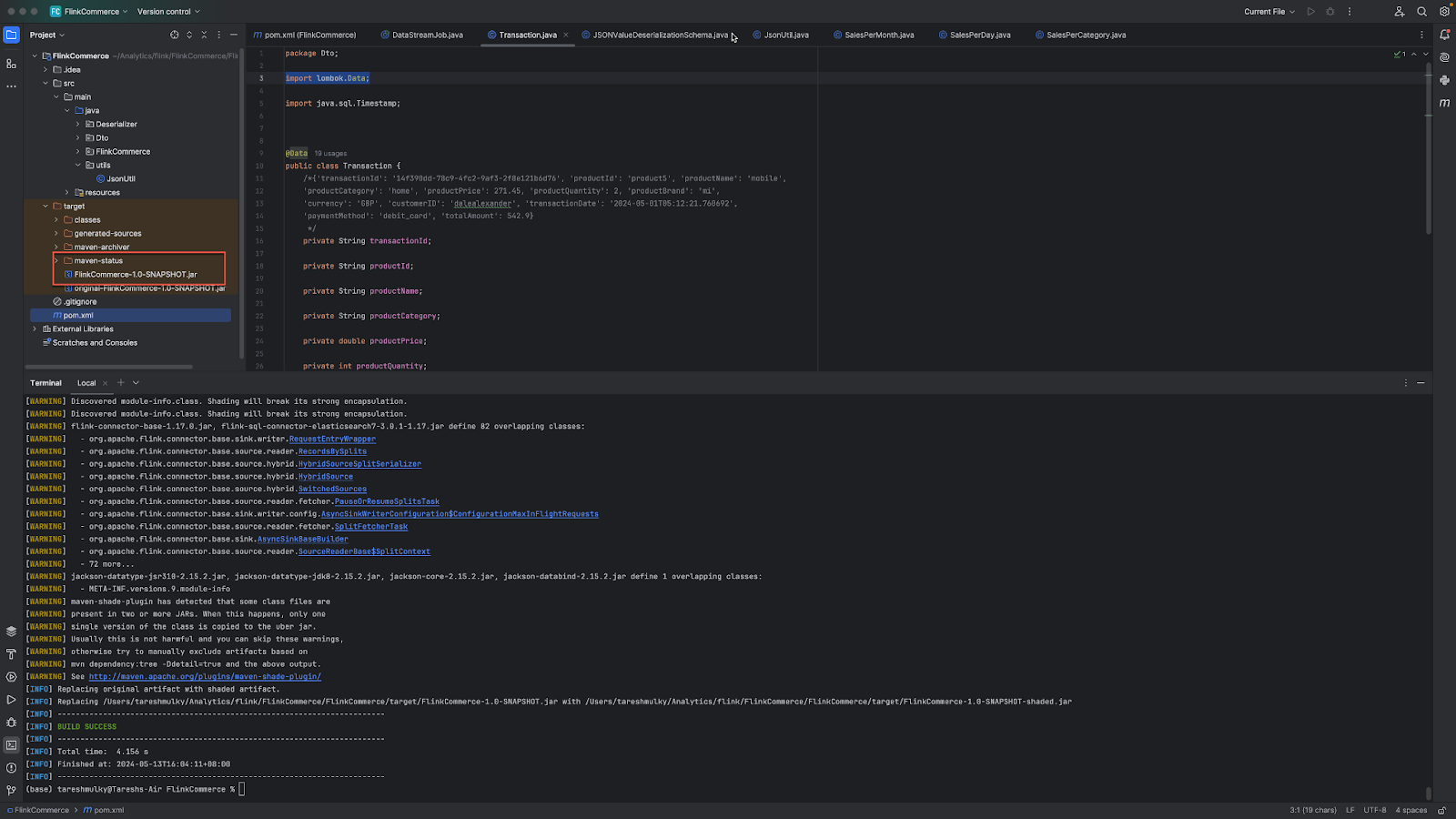
To execute, run the .jar file.
flink run -c FlinkCommerce.DataStreamJob target/FlinkCommerce-1.0-SNAPSHOT.jar
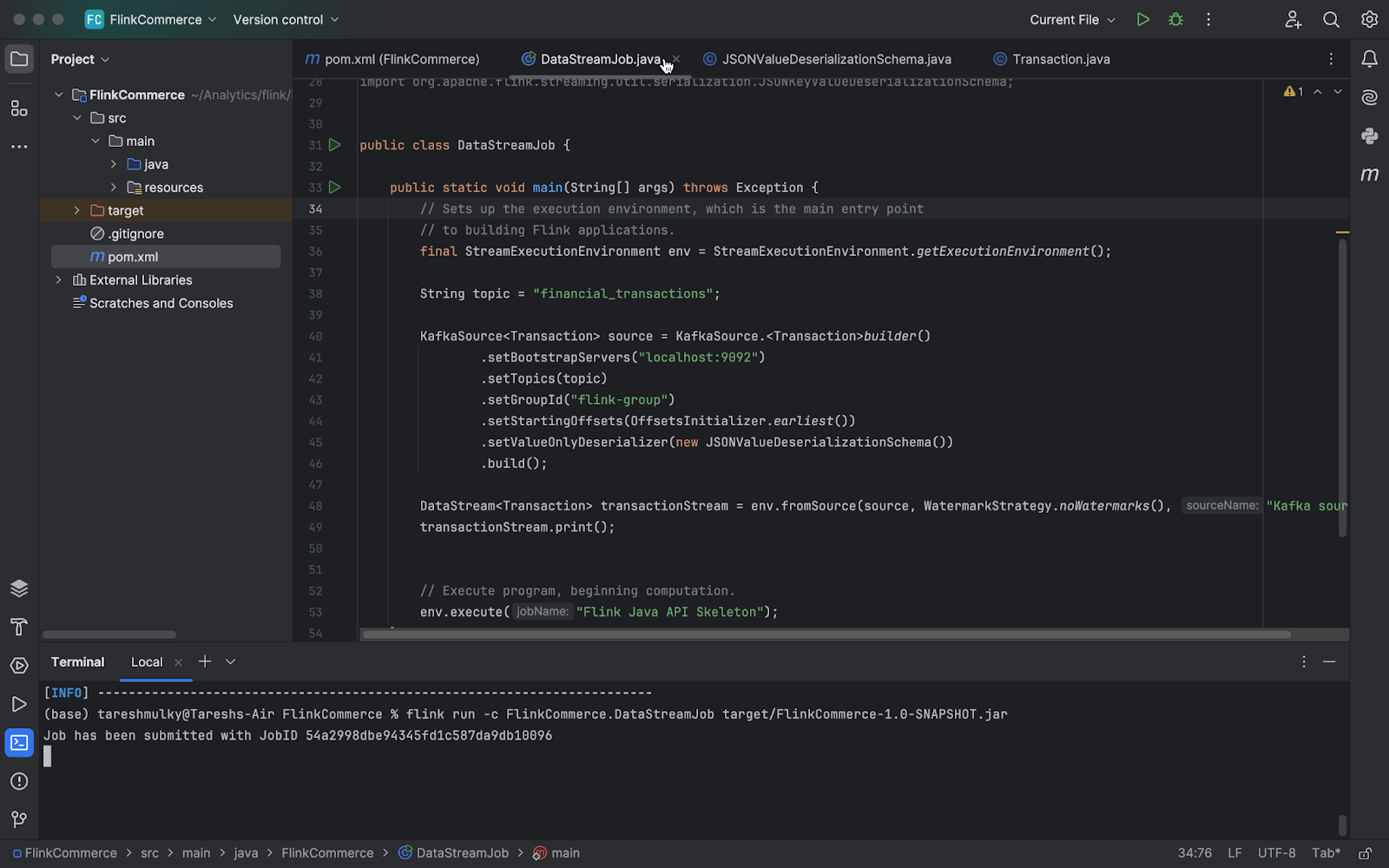
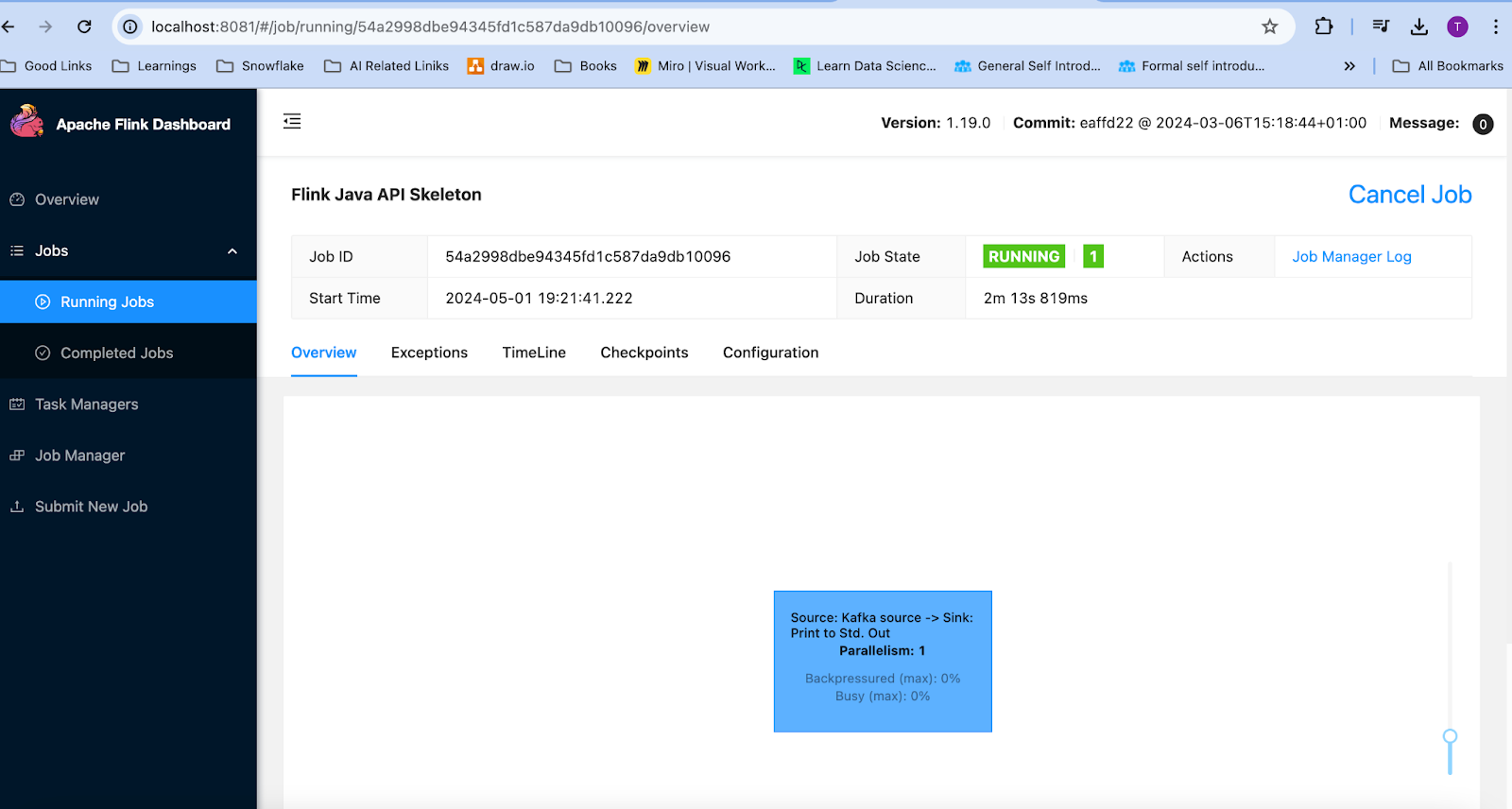
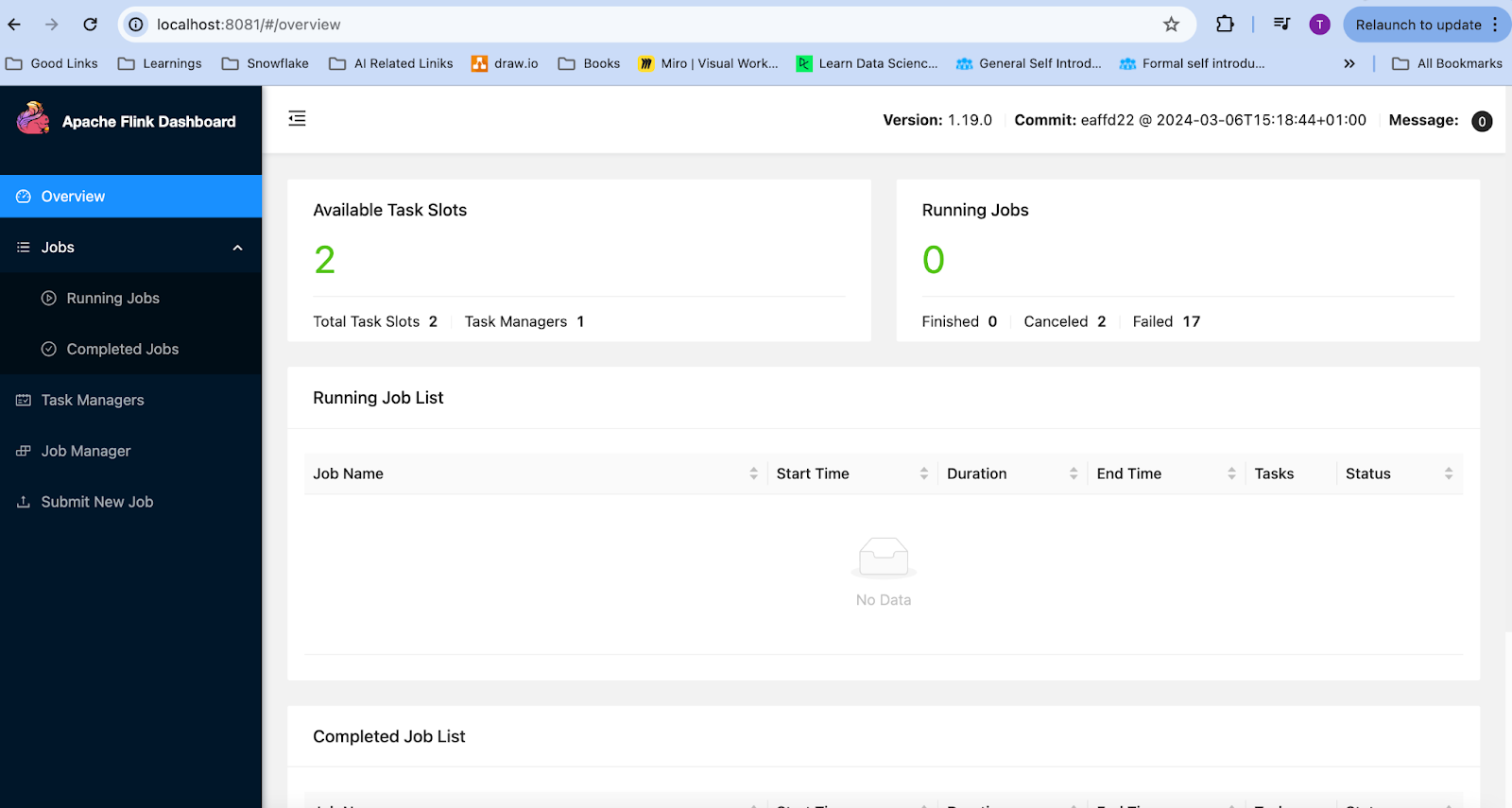
To validate that the Job is running fine, check the Flink dashboard.
You can validate that all the data is being properly deserialized.
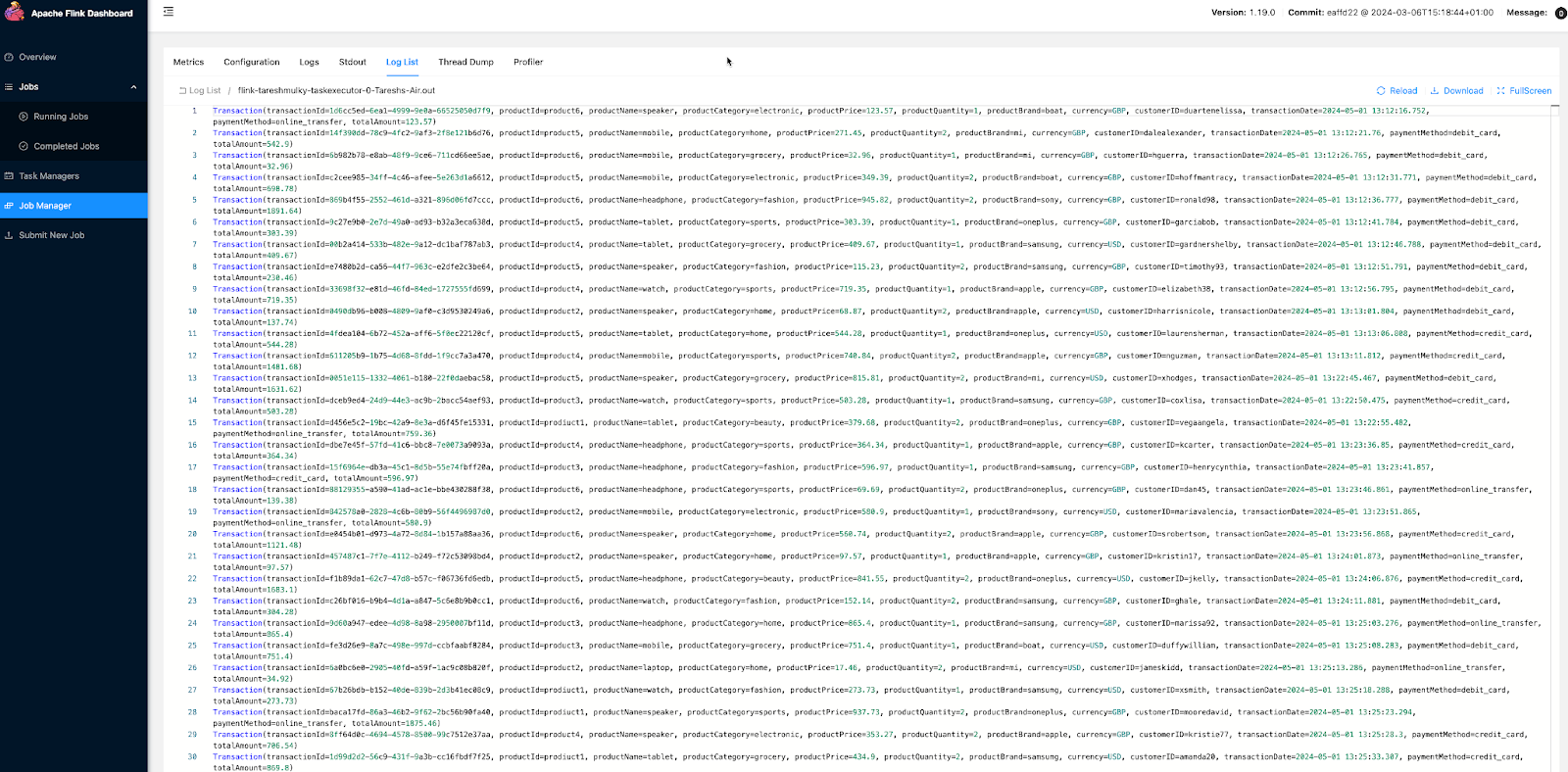
At this point, we can successfully consume data from Kafka in Flink.
Loading Data into Postgres
Create Table in Postgres
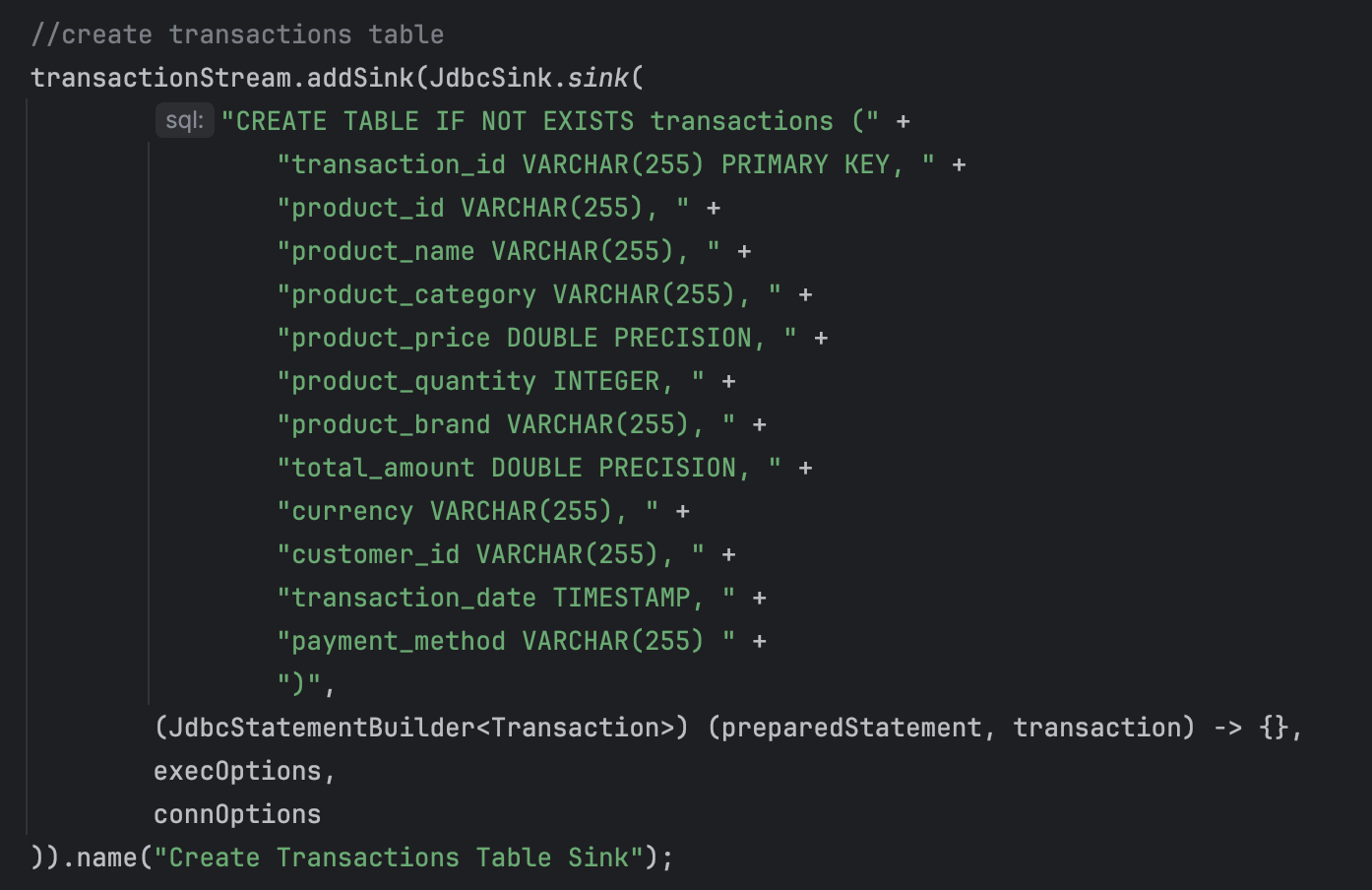
The above code is using the Flink JDBC sink to insert data from a transactionStream into a database table. The code sets up a JDBC sink in Flink to insert records from the transactionStream DataStream into a database table named transactions, creating the table if it does not already exist.
- transactionStream.addSink(...): This method is used to add a sink to the transactionStream, which is a DataStream containing Transaction objects.
- JdbcSink.sink(...): This static factory method creates a JDBC sink that writes records to a database table.
- "CREATE TABLE IF NOT EXISTS transactions ...": This string specifies the SQL statement to create the transactions table if it does not already exist. It defines the table schema with various columns such as transaction_id, product_id, product_name, etc., along with their data types.
- (JdbcStatementBuilder<Transaction>) (preparedStatement, transaction) -> {}: This lambda function is a custom implementation of the JdbcStatementBuilder interface, which defines how to execute SQL statements for each record.
- execOptions and connOptions: These are execution and connection options for the JDBC sink, specifying parameters such as the maximum number of retries, the interval between retries, and the database connection URL, username, and password.
- .name("Create Transactions Table Sink"): This method sets a name for the sink, which can be useful for monitoring and debugging purposes.
The expression (JdbcStatementBuilder<Transaction>) (preparedStatement, transaction) -> {} is a lambda expression that defines an implementation of the JdbcStatementBuilder interface for building JDBC statements to execute against a database.
Lambda Parameters
- (preparedStatement, transaction): These are the parameters of the lambda expression. The lambda expression takes two parameters: preparedStatement, which represents the prepared SQL statement that will be executed against the database, and transaction, which represents the Transaction object being processed.
Lambda Body
-> {}: This arrow (->) separates the lambda parameters from the lambda body. The lambda body is enclosed within curly braces ({}) and is empty in this case. This means that the lambda expression does not contain any additional logic for building JDBC statements
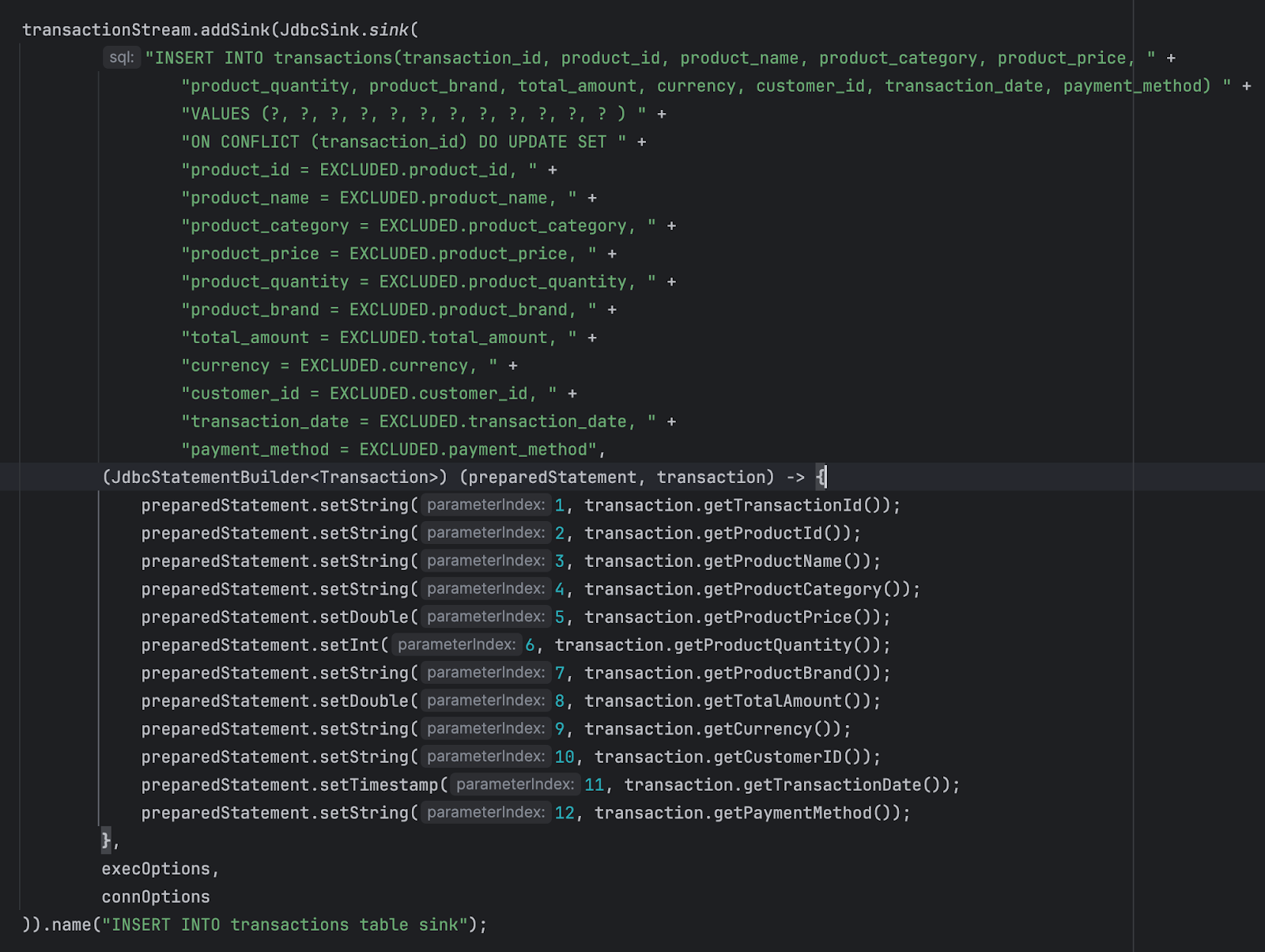
- JdbcSink.sink(...): This method creates a JDBC sink that writes records to a database table.
- SQL Statement: The first argument is the SQL statement to be executed for each record. In this case, it's an INSERT INTO ... VALUES ... ON CONFLICT DO UPDATE ... statement. This statement inserts a record into the transactions table, and if there is a conflict (e.g., duplicate transaction_id), it updates the existing record.
- JdbcStatementBuilder: The second argument is a lambda expression that implements the JdbcStatementBuilder interface. This lambda function is responsible for setting the parameters of the prepared SQL statement based on the Transaction object.
- PreparedStatement: Inside the lambda function, the preparedStatement is used to set the values of the parameters (? placeholders) in the SQL statement based on the fields of the Transaction object.
Sink Name: The .name("INSERT INTO transactions table sink") method sets a name for the sink, which can be useful for monitoring and debugging purposes.
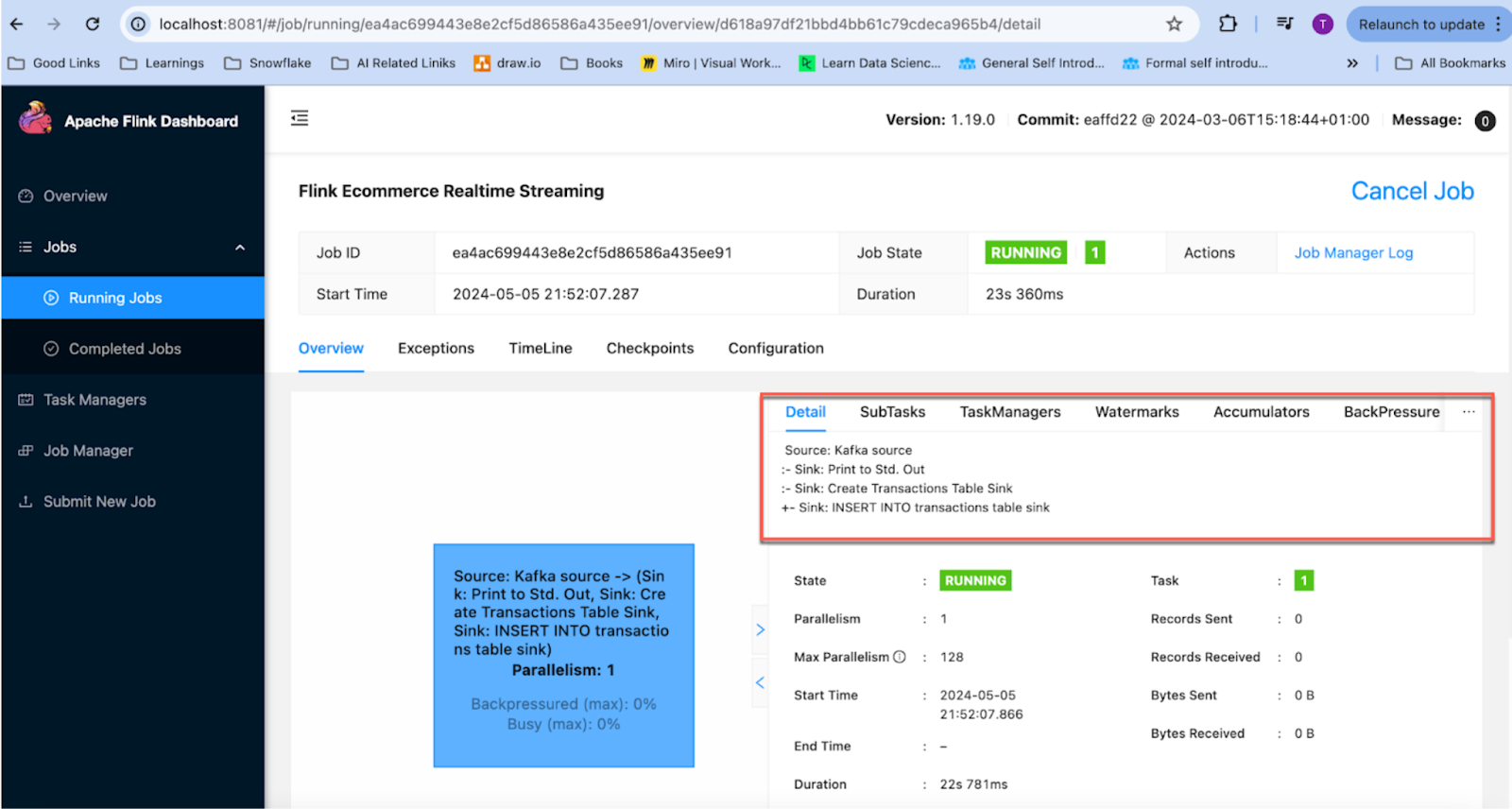
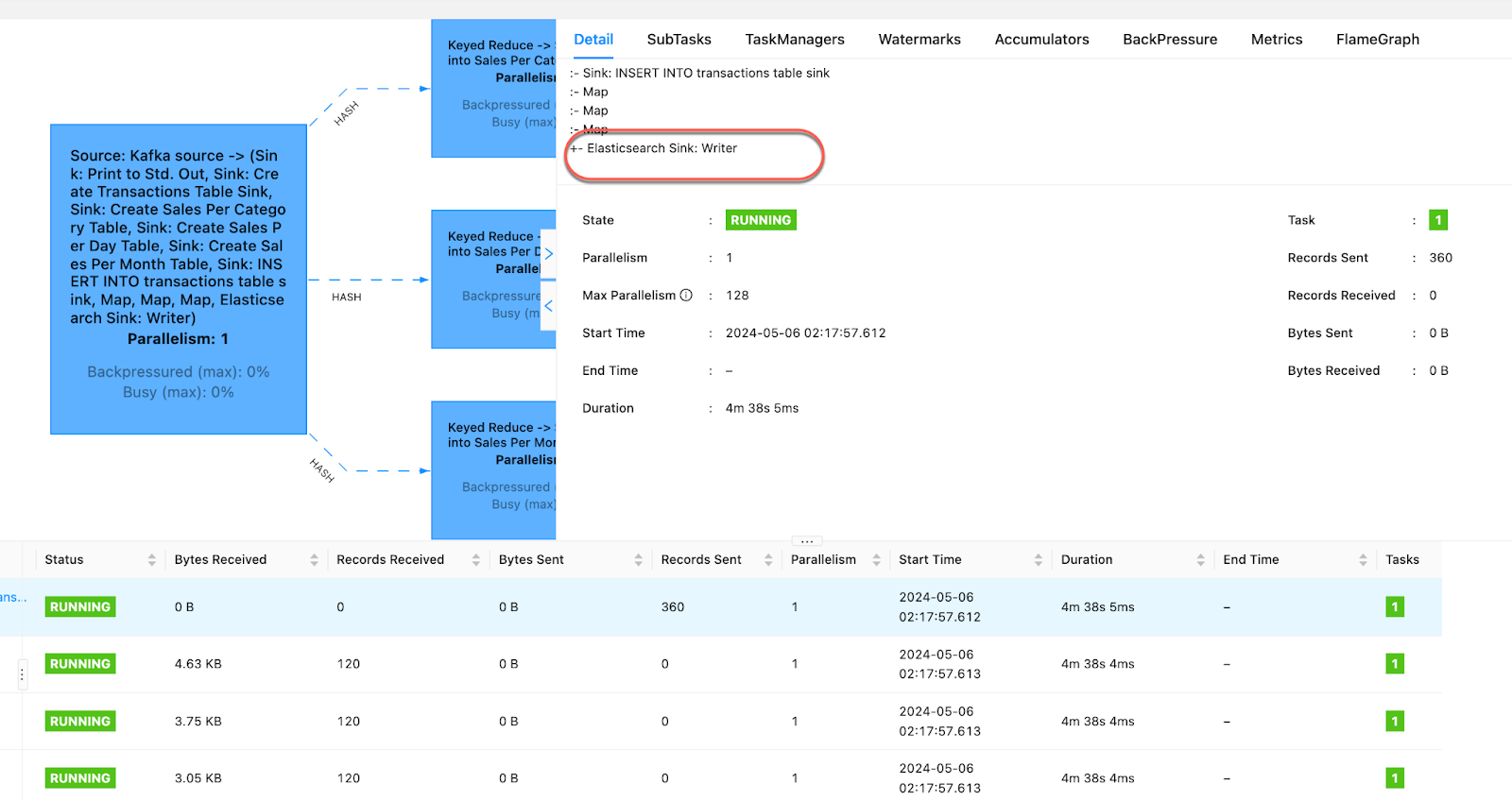
Once you compile and run the above code. You can check the Flink dashboard if everything is running ok.
And within the Docker dashboard. You should see the transactions table created in Postgres.
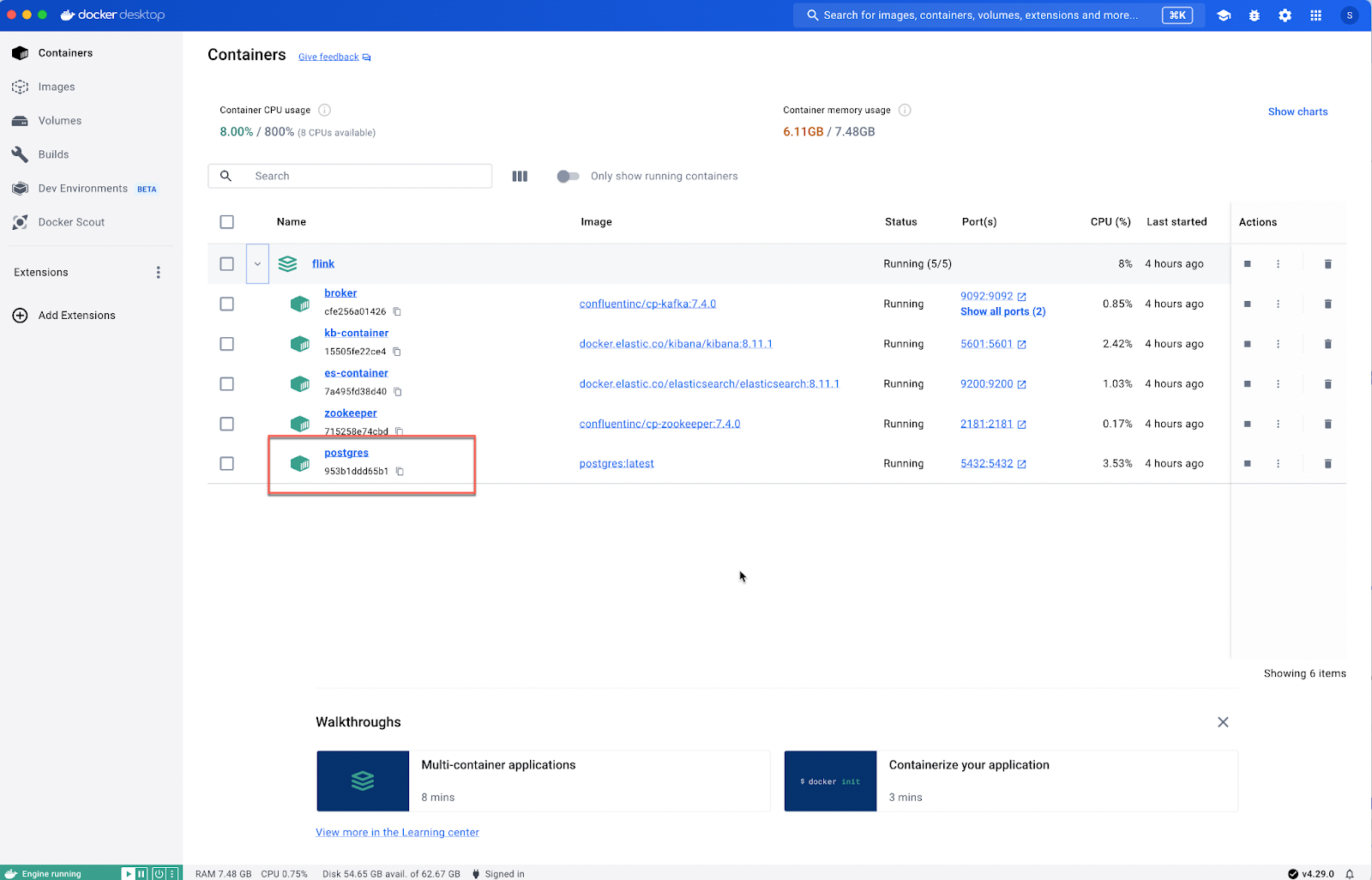
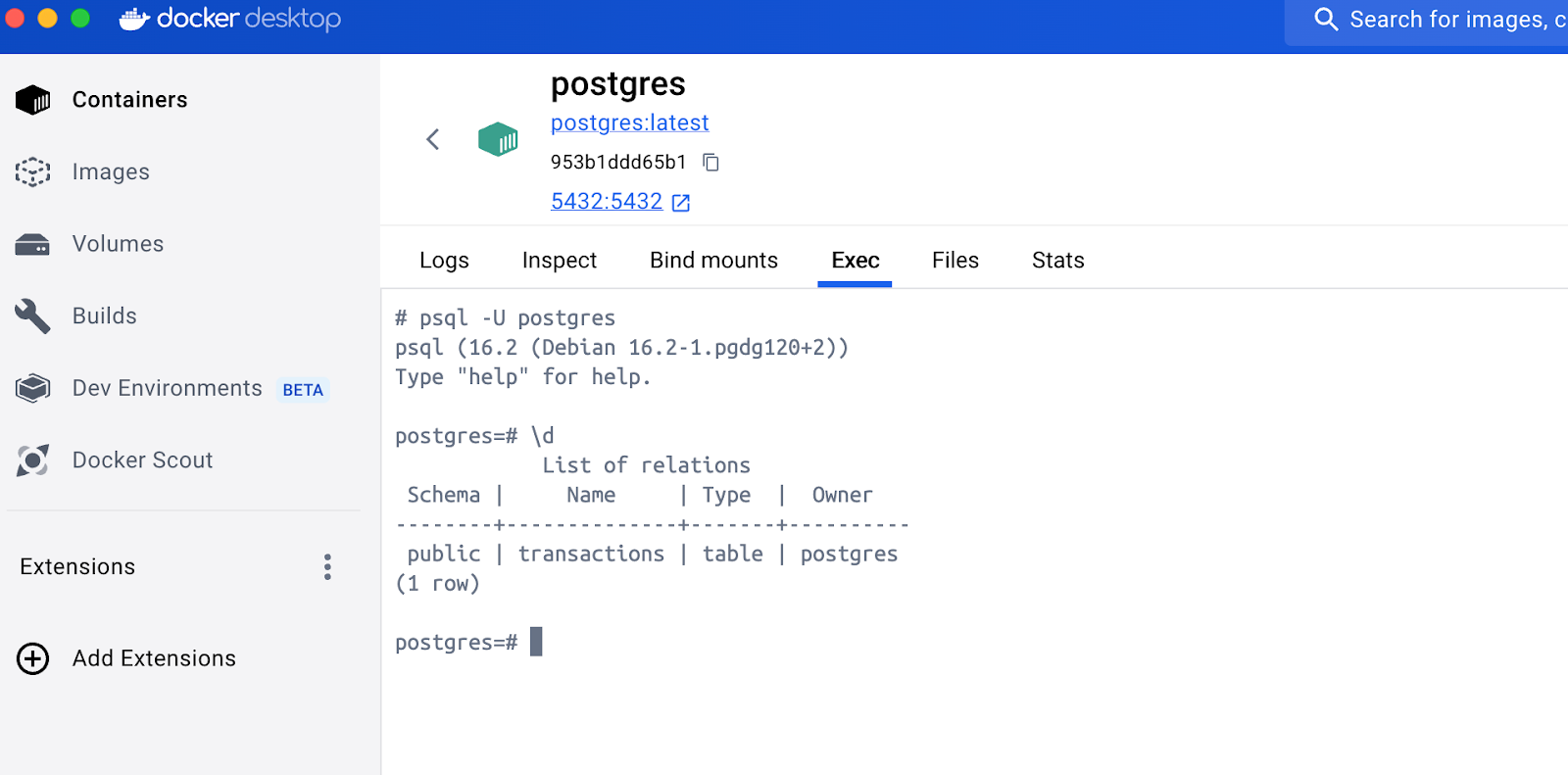
Once you run the python main.py - where we start pushing data into the Kafka Queue, you should see the records being inserted into Postgres.
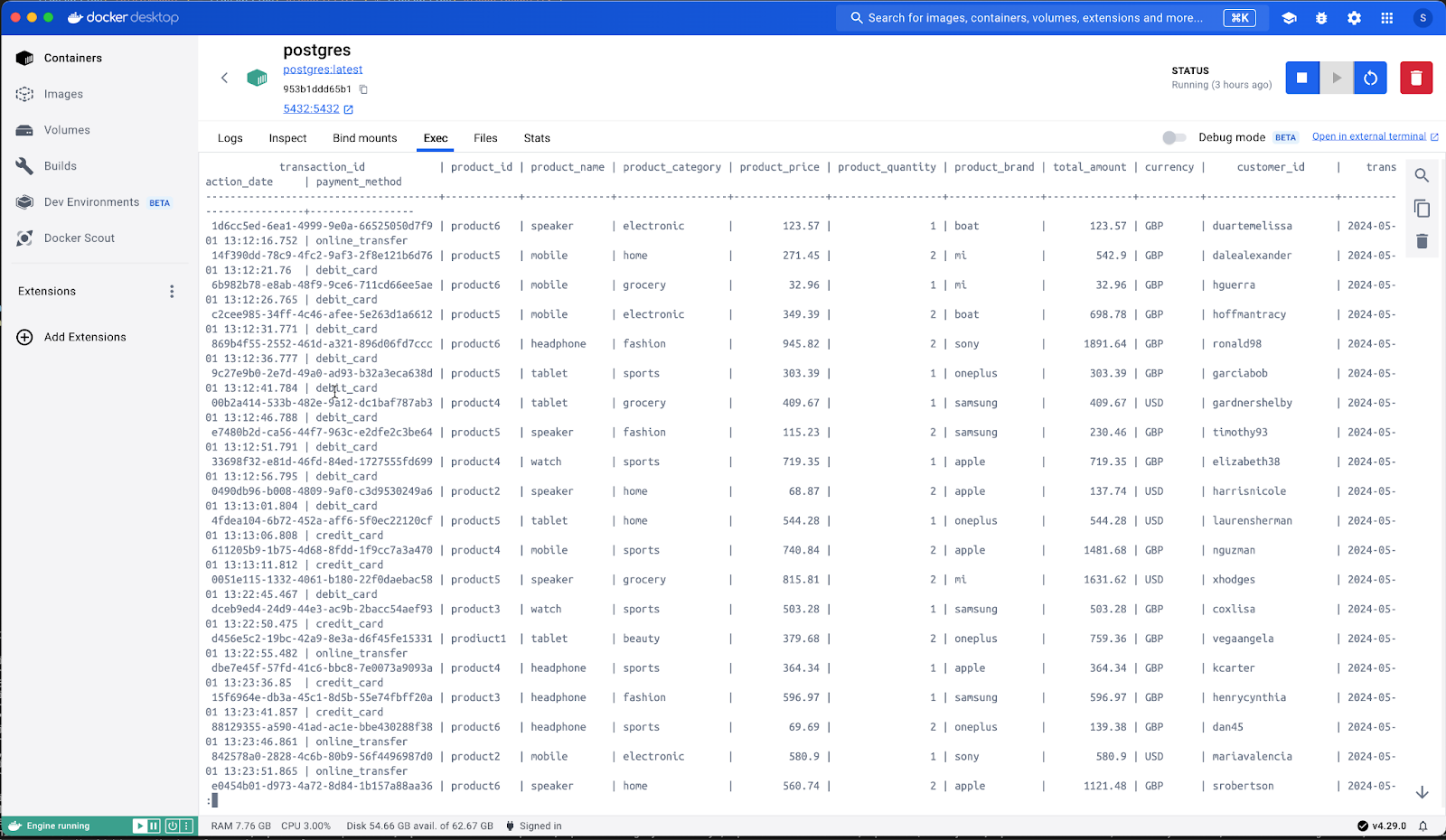
You can repeat the above steps to create additional tables in Postgres for aggregated data and insert those in. In other words, additional transformations are done in Flink before pushing it into Postgres. Additional tables such as Sales Per Category, Sales Per Day, Sales Per Month. One example below is Sales Per Category.
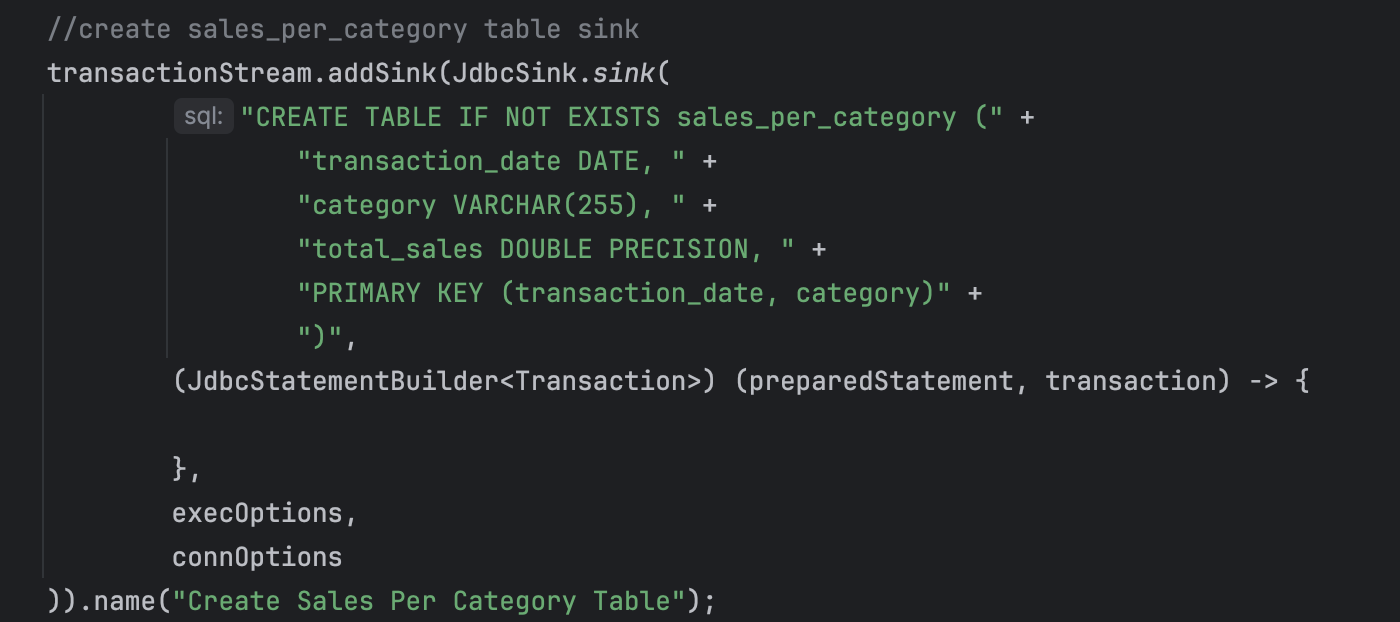
Create Sales Per Category Table
Insert into Sales Per Category
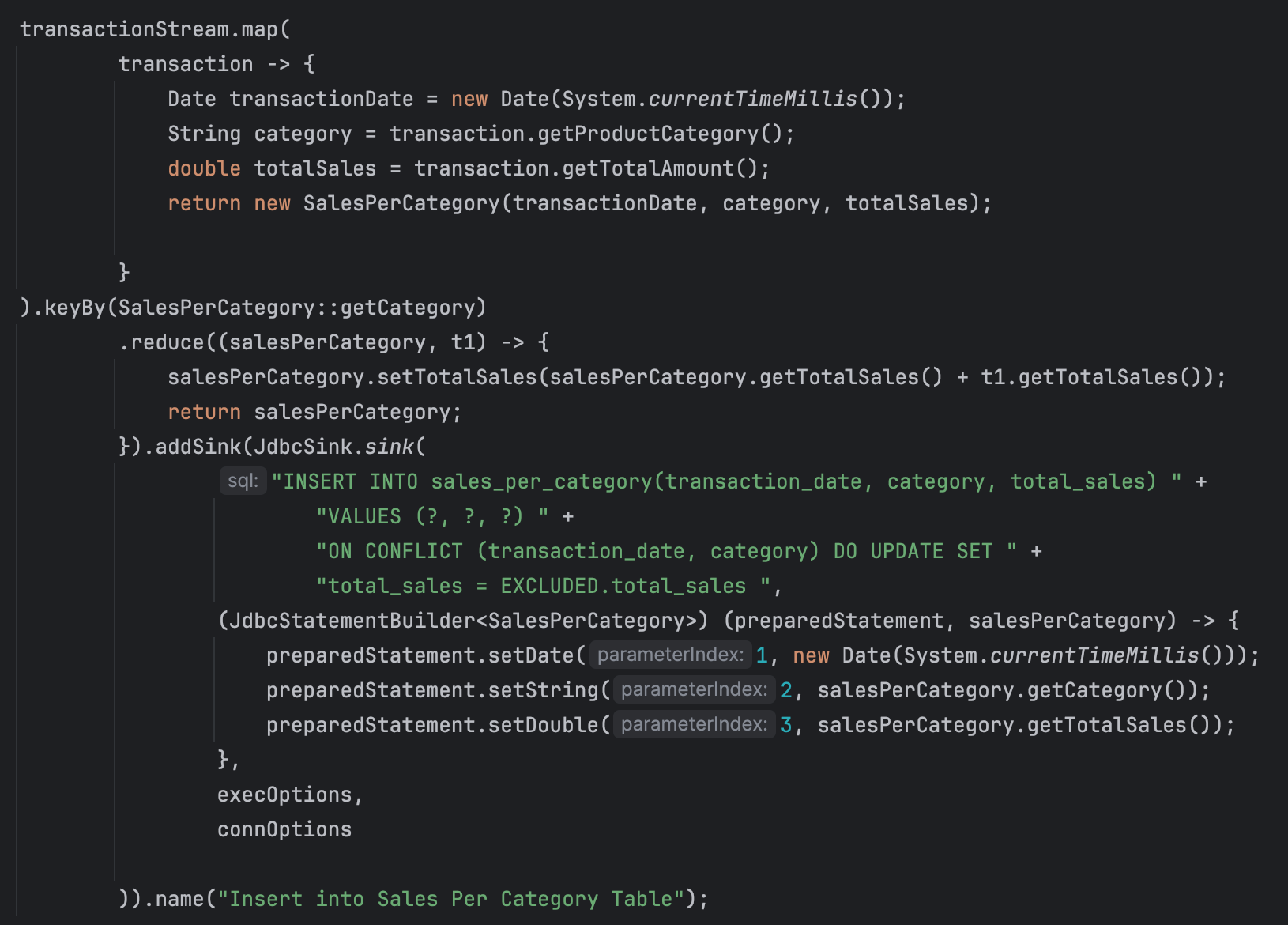
The above code processes a stream of transactions, aggregates sales data by product category, and inserts or updates the aggregated sales data into a database table using Apache Flink. Breaking down the code.
1. Mapping Transactions to SalesPerCategory:
- The map function transforms each transaction into a SalesPerCategory object. It captures the current date as the transaction date, the product category, and the total sales amount.
- The map function is applied to each transaction in the stream. It creates a new SalesPerCategory object for each transaction, capturing the current timestamp as the transaction date and extracting the category and total sales amount from the transaction.
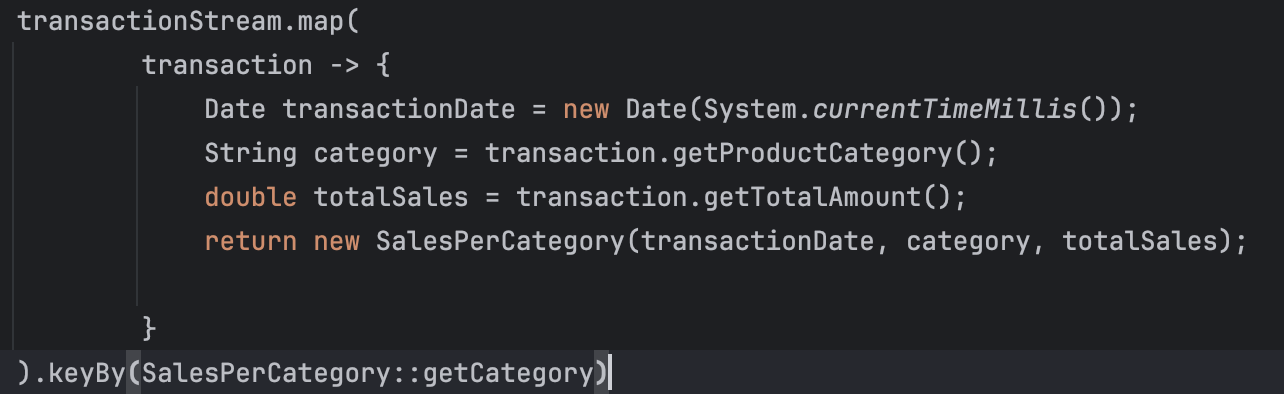
2.Keying by Category
- .keyBy(SalesPerCategory::getCategory)
- The stream is then keyed by the product category using the keyBy function. This ensures that all transactions with the same product category are processed together.
- The keyBy function partitions the stream based on the category of the product. This ensures that all transactions belonging to the same category are grouped together for further processing.
3.Reducing to Aggregate Sales
- The reduce function aggregates the total sales for each category. It combines the sales amounts of multiple SalesPerCategory objects with the same category.
- The reduce function is an operation that continuously aggregates sales amounts for each category. For each new transaction in the same category, it updates the total sales amount.

4.Inserting or Updating into Database
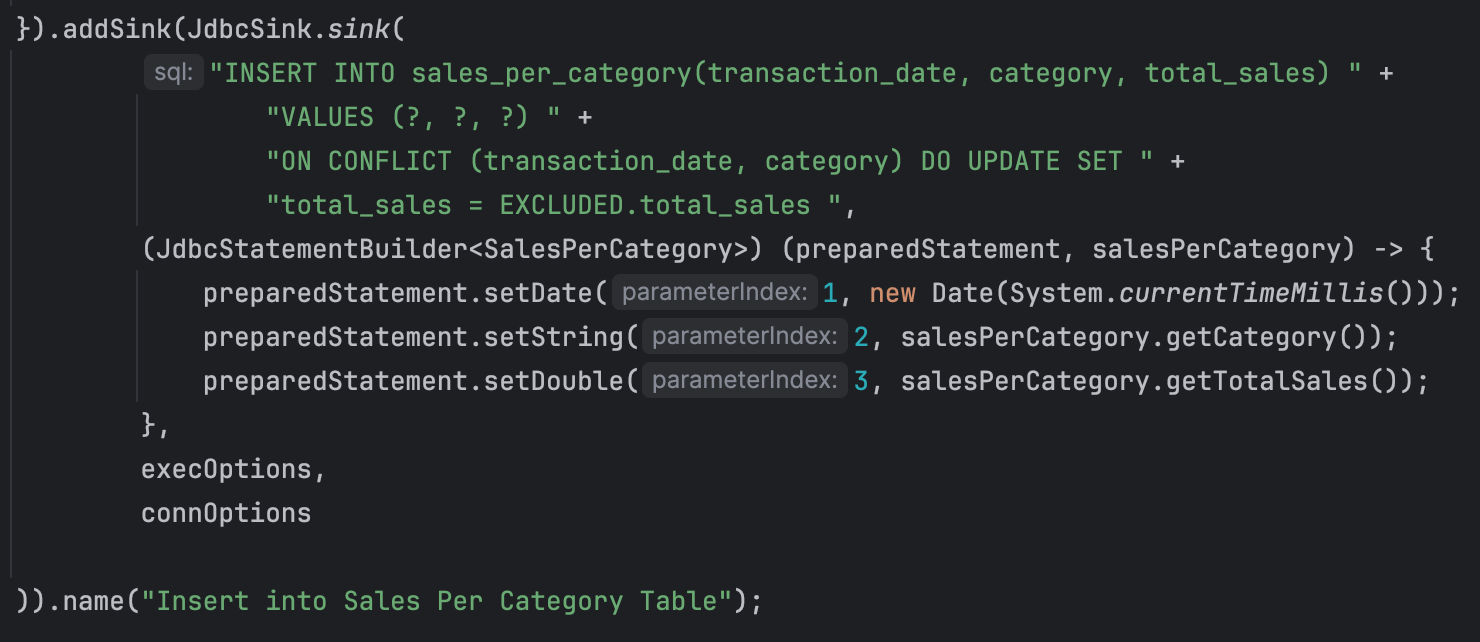
- The aggregated sales data is then written to a database table using a JDBC sink. The sink inserts new records or updates existing records if there is a conflict (i.e., if the same transaction date and category already exist).
- The addSink method specifies a JDBC sink to write the aggregated results to a relational database. The INSERT INTO ... ON CONFLICT ... DO UPDATE SQL statement ensures that the database is updated correctly, either inserting new rows or updating existing rows if a conflict on the primary key occurs.
In a retail use case, this could be used to maintain real-time analytics on sales performance across different product categories. By aggregating sales data and updating the database in real time, businesses can gain insights into sales trends, popular product categories, and overall sales performance. This information can be crucial for decision-making in areas such as inventory management, marketing strategies, and financial forecasting.
Writing Kafka Streams into Elasticsearch
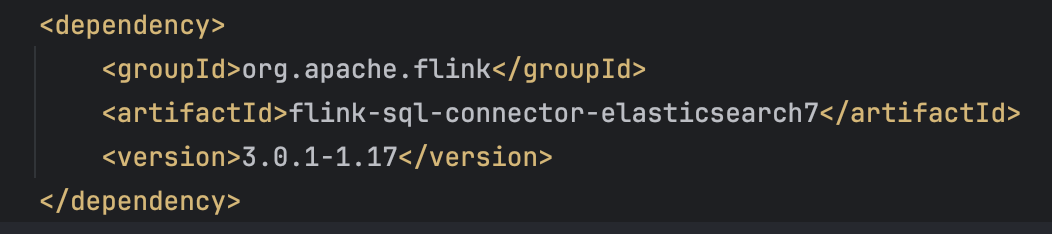
Make sure you have the dependencies in the Pom.xml file.
And check that the elasticsearch is up and running.
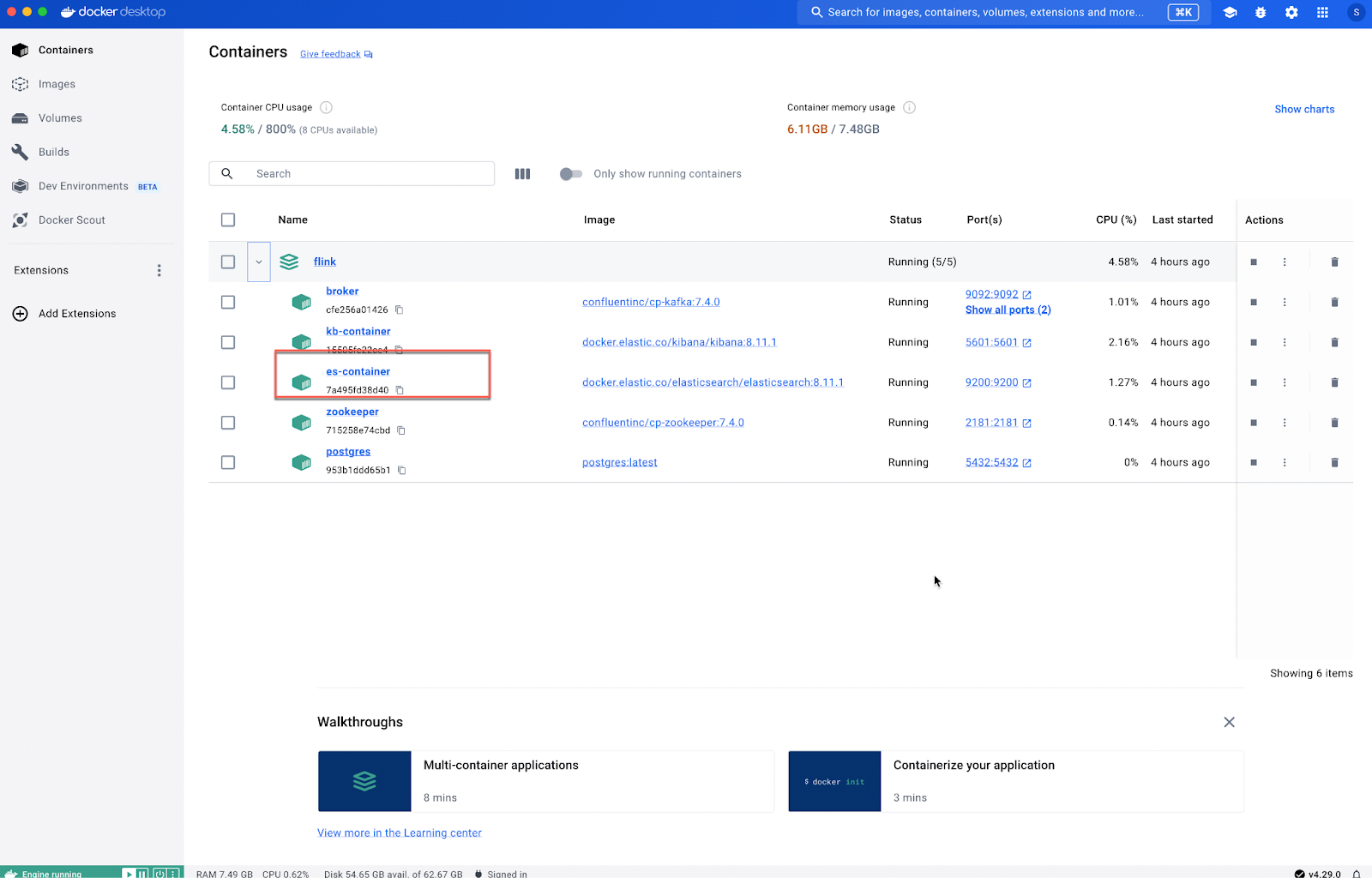
And the dashboard is up and running.
We need to create those indexes.
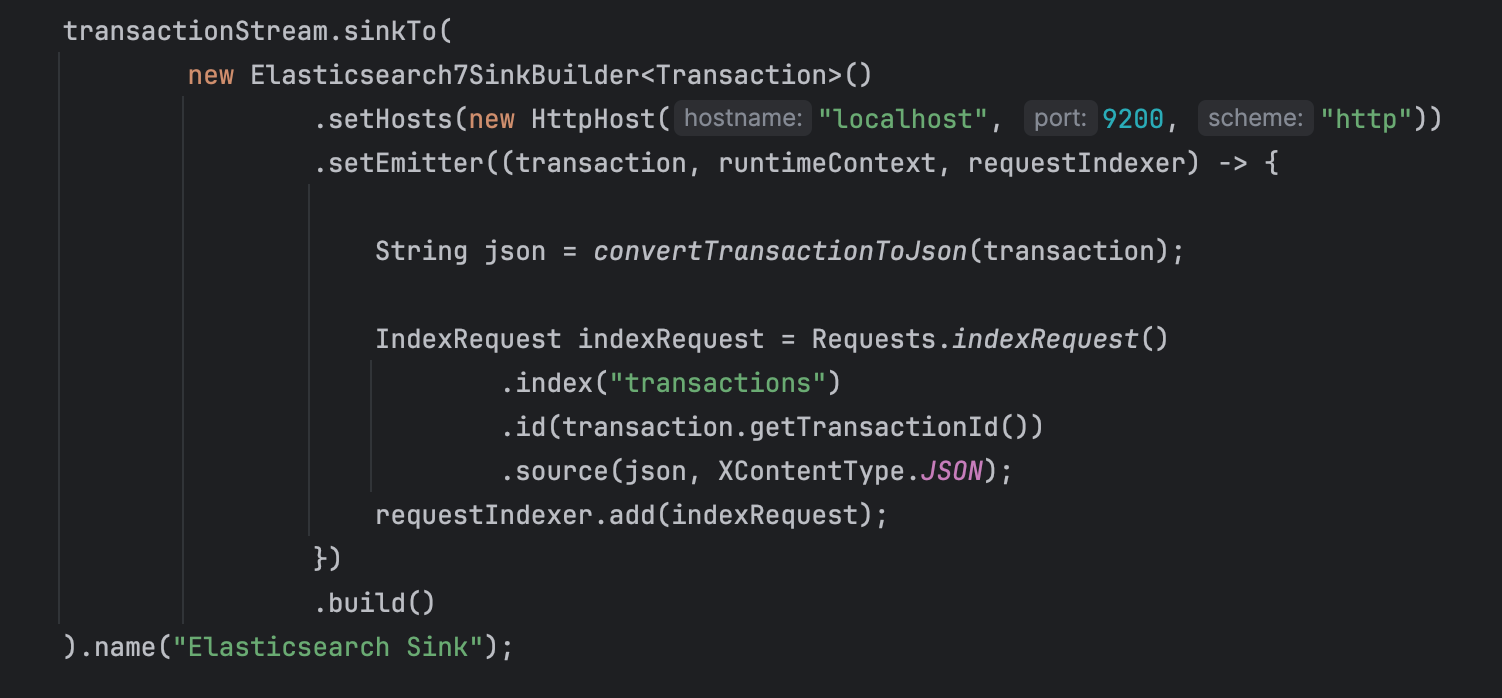
The above code configures an Elasticsearch sink in Apache Flink to index records from a transactionStream DataStream into an Elasticsearch index. This code configures an Elasticsearch sink in Flink to index records from the transactionStream DataStream into an Elasticsearch index named transactions. It uses a lambda function as the emitter to convert Transaction objects into JSON and send them to Elasticsearch for indexing.
- Elasticsearch Sink Builder: This code constructs an Elasticsearch sink using the Elasticsearch7SinkBuilder class provided by Flink's Elasticsearch connector.
- setHosts(): This method sets the Elasticsearch hosts to which the sink will connect. In this case, it sets the host to localhost and port to 9200 using the HttpHost class.
- setEmitter(): This method sets the emitter function, which is responsible for emitting records to the Elasticsearch sink. The lambda expression (transaction, runtimeContext, requestIndexer) -> { ... } represents the emitter function. It takes a Transaction object, a RuntimeContext, and a RequestIndexer as parameters. Emitter will be writing the transactions into Elasticsearch.
- Emitter Logic: Inside the lambda function, the convertTransactionToJson(transaction) method (not shown) is called to convert the Transaction object into a JSON string. Then, an IndexRequest is created using the Requests.indexRequest() method, specifying the index name (transactions), document ID (using the transactionId), and source JSON. Finally, the IndexRequest is added to the RequestIndexer to be sent to Elasticsearch.
- build(): This method builds the Elasticsearch sink with the configured properties and emitter function.
- name(): This method sets a name for the sink, which can be useful for monitoring and debugging purposes.
IndexRequest will be from Elasticsearch. The index will be called transactions.
We need to convert the transaction stream into JSON before we send it to Elasticsearch. The XContentType will be JSON. the convertTransactionToJson will be inside the package called utils. JsonUtil.java
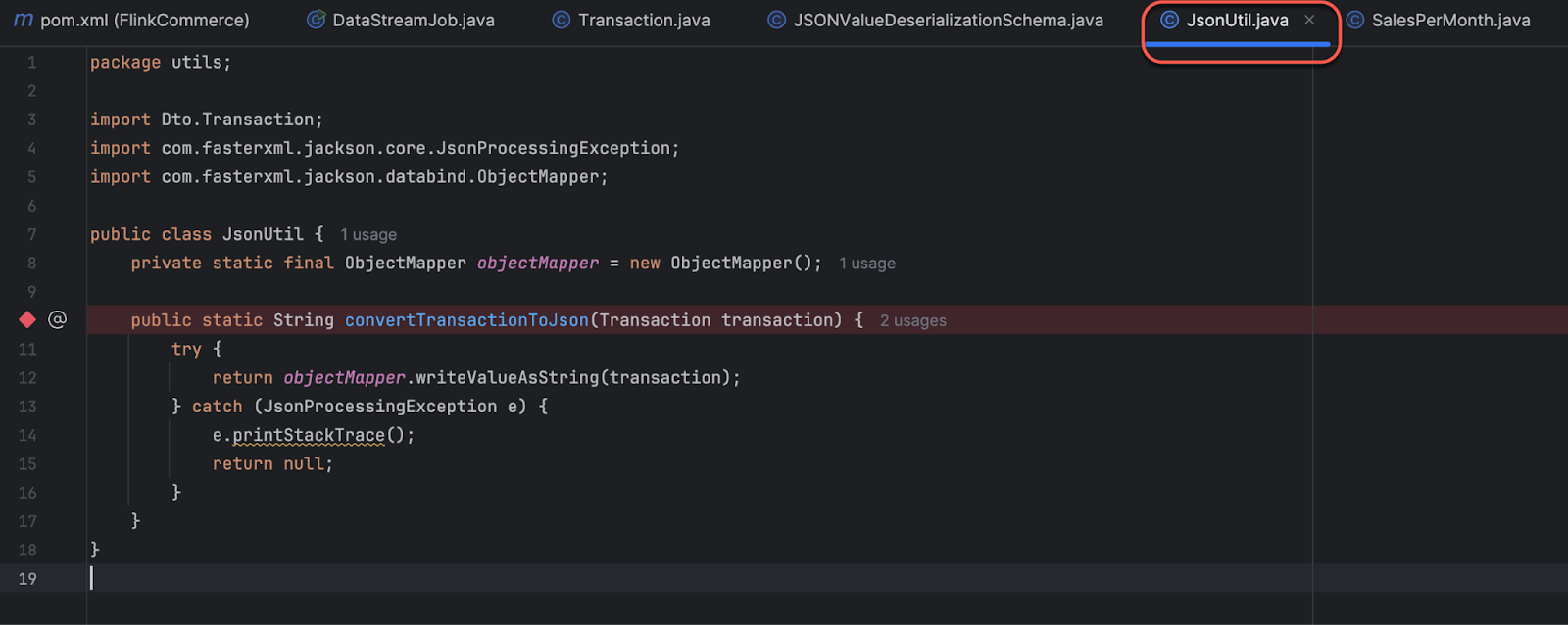
The above code is a utility class named JsonUtil, which contains a static method convertTransactionToJson() for converting a Transaction object to a JSON string using the Jackson library.
- Package Declaration: This class is declared in the utils package.
- Import Statements:
- import Dto.Transaction;: This imports the Transaction class from the Dto package.
- import com.fasterxml.jackson.core.JsonProcessingException;: This imports the JsonProcessingException class from the Jackson library. It is used to handle exceptions related to JSON processing.
- import com.fasterxml.jackson.databind.ObjectMapper;: This imports the ObjectMapper class from the Jackson library. The ObjectMapper class is used for JSON serialization and deserialization.
- Static ObjectMapper: The class contains a static variable objectMapper of type ObjectMapper, which is used for converting objects to JSON strings and vice versa. Declaring it as static ensures that there is only one instance of ObjectMapper shared across all instances of JsonUtil.
convertTransactionToJson() Method: This is a static method that takes a Transaction object as input and returns its JSON representation as a string. Inside the method:
- The writeValueAsString() method of the objectMapper is used to convert the Transaction object to a JSON string.
Once done, clean, compile and Package again. - Then check Flink dashboard - Elasticsearch should be there.
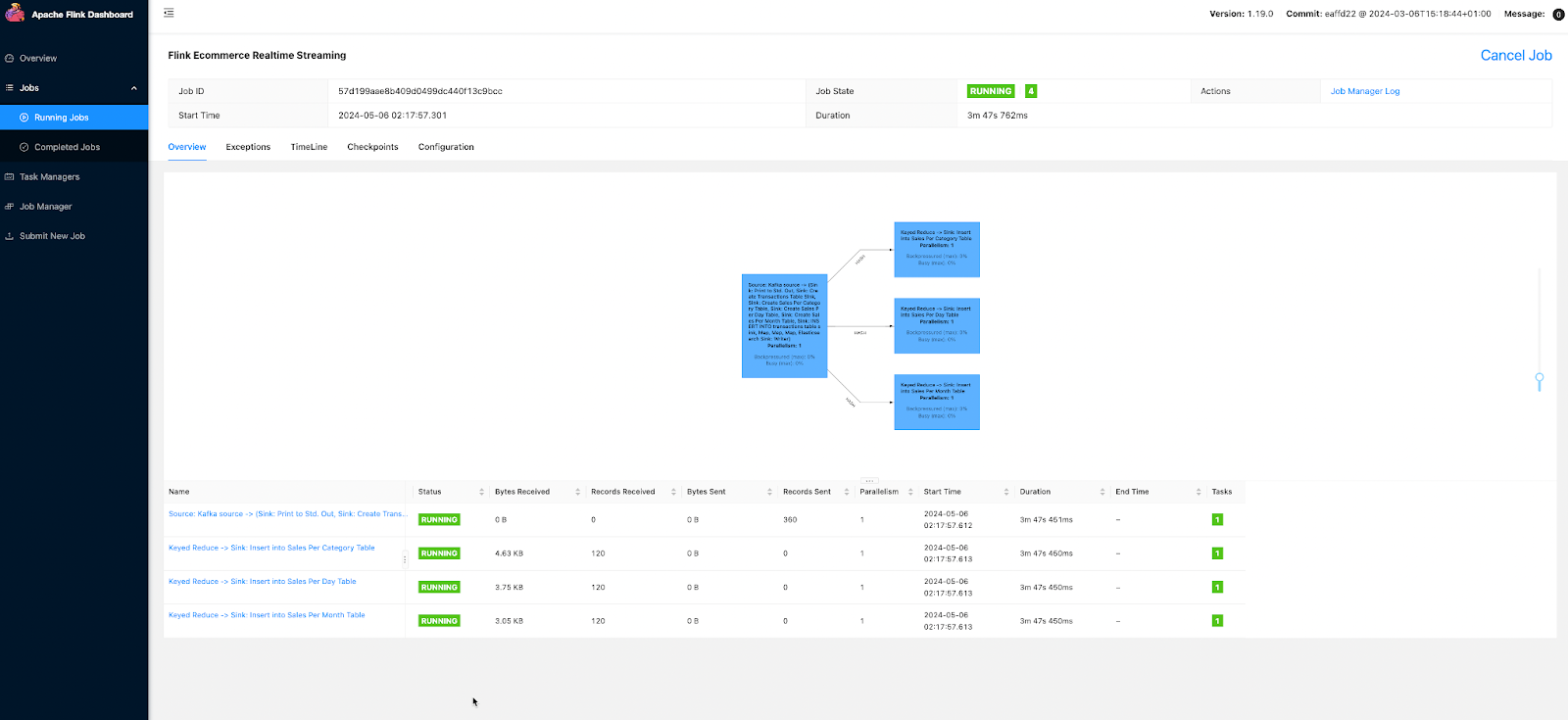
If this is successful, go to elastic search and you should see the transactions in JSON format.
GET transactions/_search
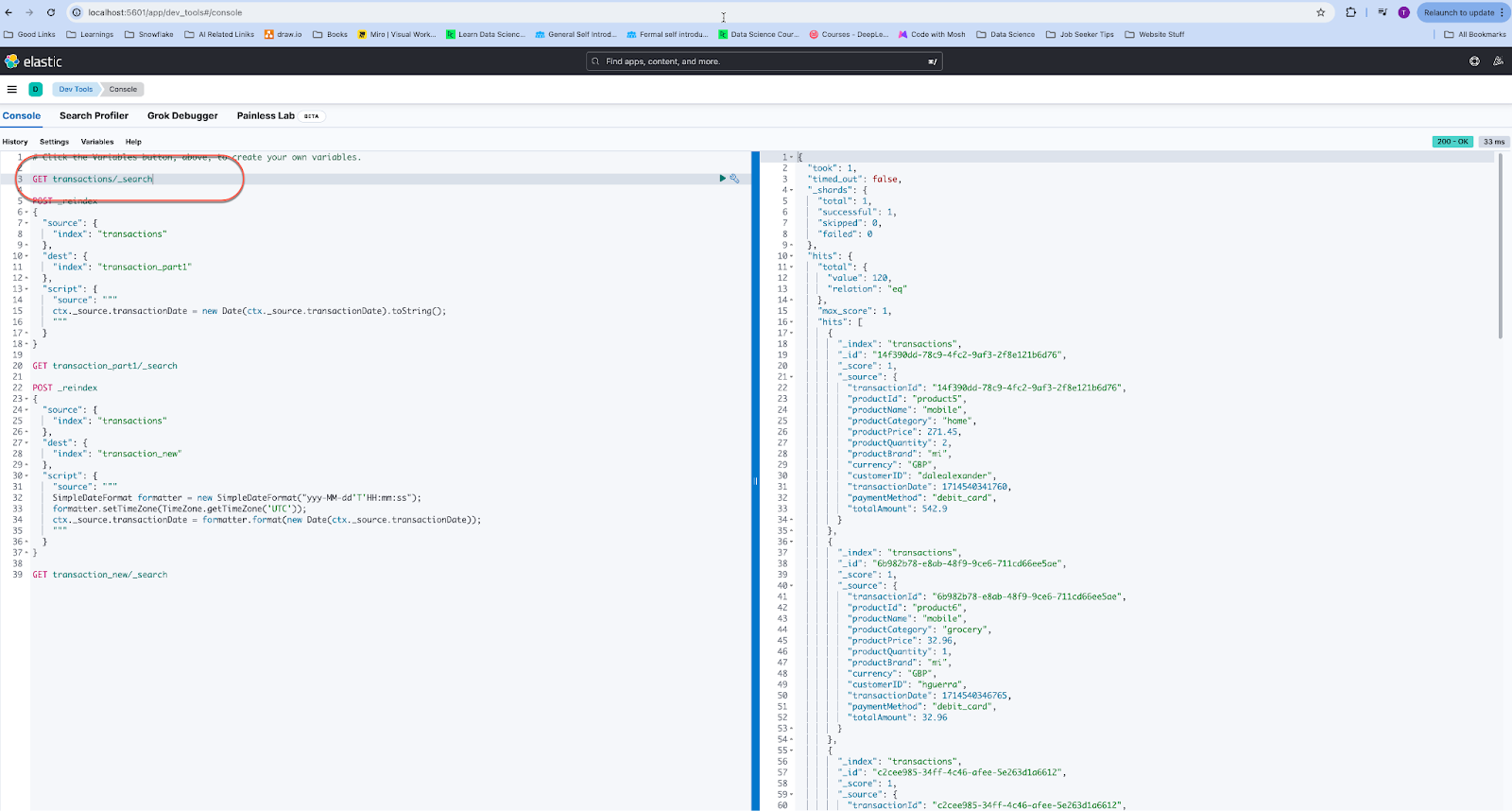
But since the format of the date is incorrect, we could either fix it here or at Flink. We could reindex it here.
Reindexing data on elasticsearch with Timestamp

The Elasticsearch _reindex request is used to copy documents from one index (transactions) to another index (transaction_part1), while also applying a transformation to the documents using a script.
- Source Index:
- "source": { "index": "transactions" }: Specifies the source index from which documents will be copied. In this case, it's the transactions index.
- Destination Index:
- "dest": { "index": "transaction_part1" }: Specifies the destination index to which documents will be copied. In this case, it's the transaction_part1 index. If the destination index does not exist, Elasticsearch will create it.
- Transformation Script:
- "script": { "source": "...script code..." }: Specifies a script to be executed for each document during the copying process. In this case, the script modifies the transactionDate field of each document.
- ctx._source.transactionDate = new Date(ctx._source.transactionDate).toString();: This script converts the transactionDate field of each document from its current format (presumably a date) to a string representation of the date. It uses JavaScript's Date constructor to parse the existing date and then calls toString() to convert it to a string. The modified transactionDate field is then assigned back to ctx._source.transactionDate.
- "script": { "source": "...script code..." }: Specifies a script to be executed for each document during the copying process. In this case, the script modifies the transactionDate field of each document.
Build dashboards in Kibana
Create a data view
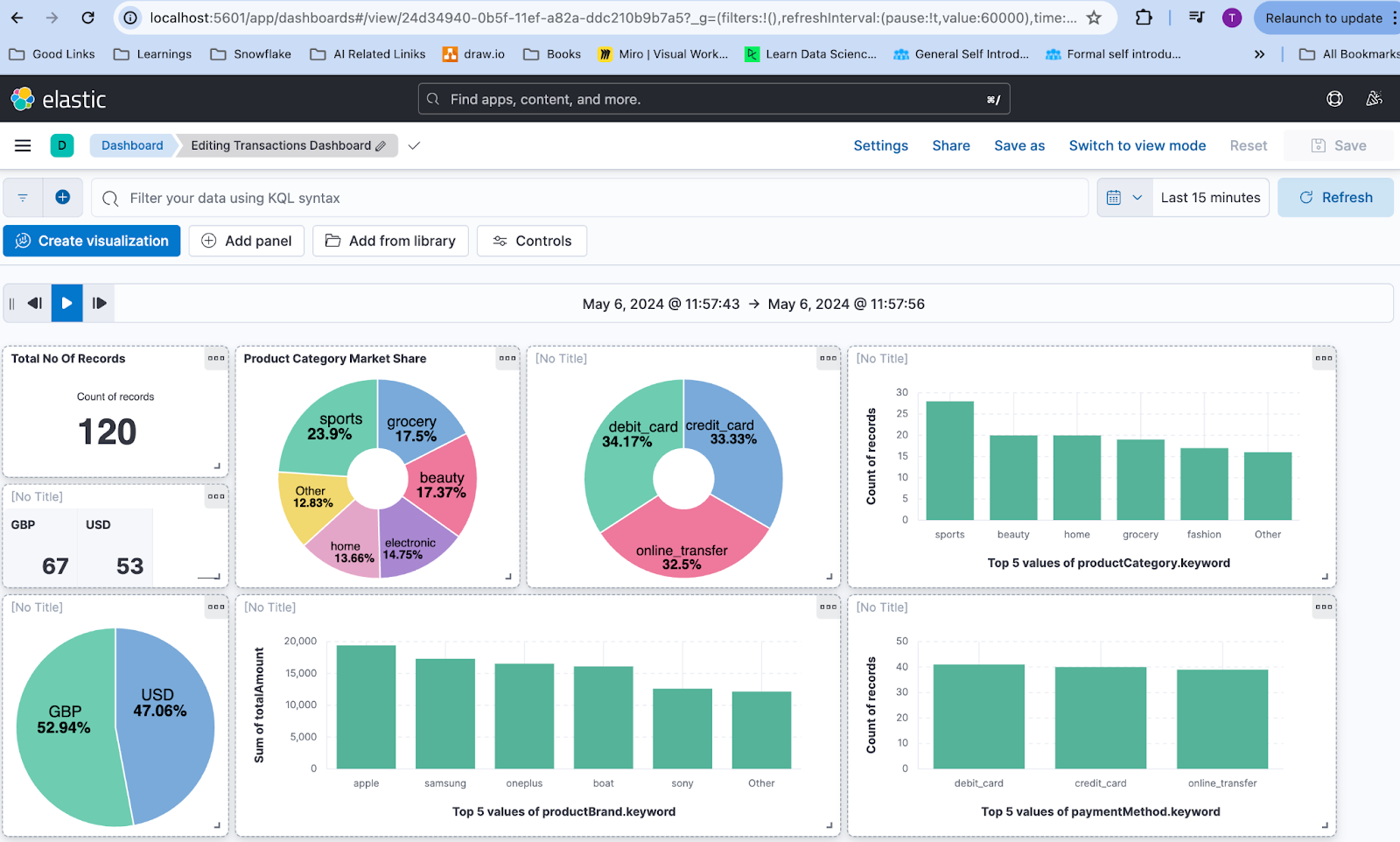
Once done you can create the dashboard to be refreshed at certain times.
Resources
This project would not have been possible without the support and guidance from Yusuf Ganiyu & his articles. Since I had to set everything from start, everything had to be installed.
Dockers
Docker is mainly a software development platform & a kind of virtualization technology that makes it easy to develop & deploy apps inside of neatly packed virtual containerized environments.
Docker is a platform that enables developers to build, ship, and run applications inside containers. Containers are lightweight, portable, and self-sufficient environments that package everything needed to run an application, including code, runtime, system tools, libraries, and settings. Docker provides tools and workflows for managing containers efficiently across different environments, from development to production.
Kafka Broker
A Kafka broker is a key component of Apache Kafka, an open-source distributed streaming platform used for building real-time data pipelines and streaming applications. Apache Kafka, an open-source distributed event streaming platform and it has emerged as a game-changer, reshaping the landscape of data architecture. At its core, Apache Kafka is a distributed streaming platform designed for building real-time data pipelines and streaming applications. It excels in handling and processing vast volumes of data streams across distributed environments.
Key Components of Kafka:
- Producers: Entities responsible for publishing data or events to Kafka topics.
- Topics: Logical channels or categories that categorize data streams.
- Brokers: Kafka servers that manage and store data.
- Consumers: Entities that subscribe to topics and process the data streams.
In a retail application, a Kafka broker serves as a fundamental component for managing real-time data streams and facilitating various functionalities.
For example: Real-time Inventory Management: Kafka brokers can handle streams of data related to inventory updates, such as stock levels, product movements, and orders. Retailers can use Kafka to ensure that their inventory systems are always up to date, allowing them to avoid stockouts or overstock situations.
Maven
Maven is a powerful build automation tool primarily used for Java projects. It simplifies and standardizes the process of managing a project's build configuration, dependencies, and deployment. Maven is written in Java and C# and is based on the Project Object Model (POM). POM is an XML file that has all the information regarding project & configuration details. To download dependencies, you could access https://mvnrepository.com/
The Maven Central Catalog, often referred to simply as the Maven Central Repository or Maven Repository, is a comprehensive index of artifacts (JAR files, libraries, and other resources) hosted on Maven Central. It acts as a catalog or directory of all the available dependencies that developers can include in their projects.
Apache Flink
Apache Flink is an open-source stream processing framework for real-time data analytics and event-driven applications. It provides powerful capabilities for processing and analyzing continuous streams of data with low latency, high throughput, and fault tolerance. Apache Flink is a powerful and flexible stream processing framework that empowers organizations to build real-time data applications for a wide range of use cases, including real-time analytics, fraud detection, recommendation systems, monitoring, and more. Its rich feature set and scalability make it a popular choice for building modern data-driven applications in the era of big data and IoT.
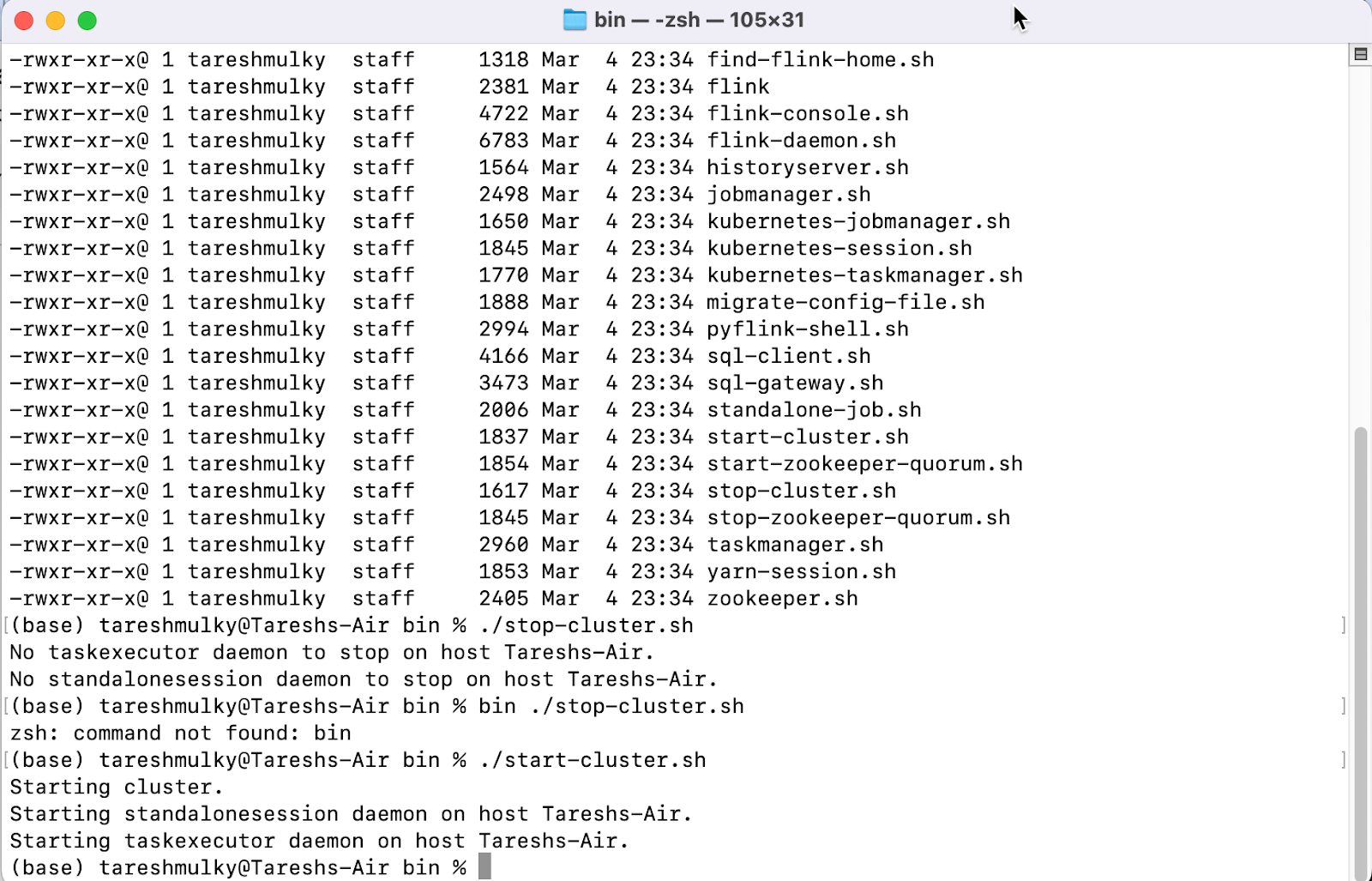
Start the Flink Cluster
./start-cluster.sh
Elasticsearch
Elasticsearch is an open-source distributed search and analytics engine designed for storing, searching, and analyzing large volumes of structured and unstructured data in real time. It is part of the Elastic Stack (formerly known as the ELK Stack), which also includes Kibana for data visualization. Overall, Elasticsearch is widely used for a variety of use cases, including log and event data analysis, full-text search, monitoring and observability, application performance monitoring (APM), security analytics, and more. Its combination of search, analytics, scalability, and real-time capabilities makes it a versatile tool for building modern data-driven applications and solutions.
Thank you for reading.


